
A few weeks back, I had the pleasure of giving one of the four talks on the ML in Product Talk at the Strata OReilly Superstream. Since the Strata in-person conference got canceled, the fantastic folks at OReilly organized an extremely well-attended livestream with active Q&A. We had over a thousand attendees dial in and fielded 100+ questions!
At Verta, we build open-core ML Infrastructure to enable companies to operationalize their ML models (i.e., run them, operate them, and maintain them long term). As a result, the topic of my talk at Strata was Robust MLOps with Open-Source:ModelDB, Docker, Jenkins, and Prometheus. My talk covers the need for MLOps, what we can borrow from DevOps, and a hands-on exercise in building a real-world MLOps pipeline.
Given the popularity of the talk and interest in MLOps, we wanted to share this recap of the talk. In addition, you can find the accompanying slides here, the recorded talk on Verta’s Youtube Channel, and the code for the hands-on part of the talk here.
Here’s what we will cover in this this post:
- What is MLOps?
- Building an MLOps Pipeline
- Real-world Simulations
- Let’s fix the pipeline
- Wrap-up
We will be doing detailed blog posts on different breakout topics identified above in the coming weeks, so stay tuned via Slack or via our newsletter.
Why MLOps?
As software was eating the world in 2011, ML is eating the world in 2020. Entire products (e.g., email with SmartCompose, personal assistants like Alexa) are getting rewritten with ML at their core. Due to the huge surge of research in deep learning and generally machine learning in the last 8 years (after the watershed moment of AlexNet), it has become reasonably easy to build ML models. We have a host of pre-trained models (e.g., TensorFlow hub, PyTorch hub) that make the best-in-class models available to every data scientist in the world. Add to that the huge improvements in libraries in scikit-learn and xgboost, and large number of resources like Fast.ai, bootcamps, Medium blogs, and data science resources.
At the same time, bringing models into production (i.e., running them, scaling and maintaining them, and integrating them into products) remains a huge challenge as illustrated by the following Tweets and case studies from different industries.
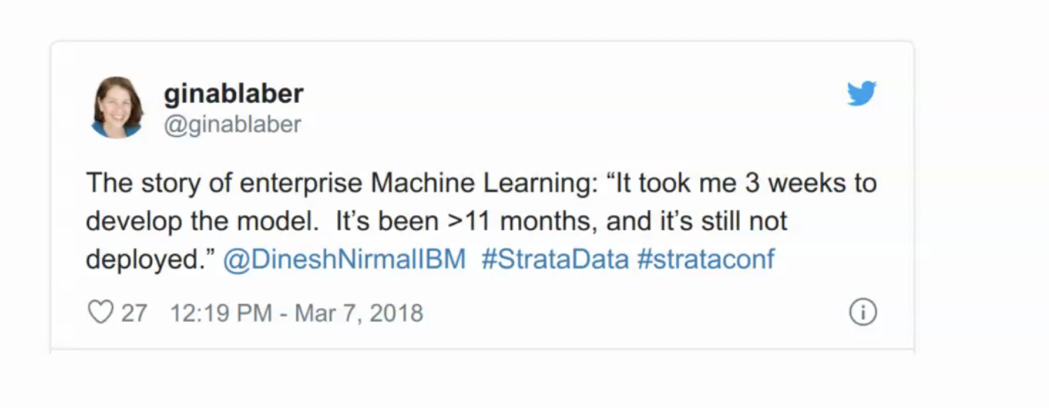 Ref: https://twitter.com/ginablaber/status/971450218095943681?lang=en
Ref: https://twitter.com/ginablaber/status/971450218095943681?lang=en

Ref: https://blog.verta.ai/blog/case-study-data-science-at-leadcrunch

Ref: https://conferences.oreilly.com/strata/rx2013/public/schedule/detail/29798
We have been building and deploying software for decades now, and yet the delivery and operations for models remains challenging. There are three reasons for that:
- Model Development very different from Software Development: it is empirical and ad-hoc
- Data Scientists use very different tools and have a different skillset than Software engineers
- Current software development and delivery tools are not ML-aware.
Given the unique challenges in operationalizing ML, a new set of tools and job category is developing called MLOps, i.e., DevOps for ML.
What is MLOps?
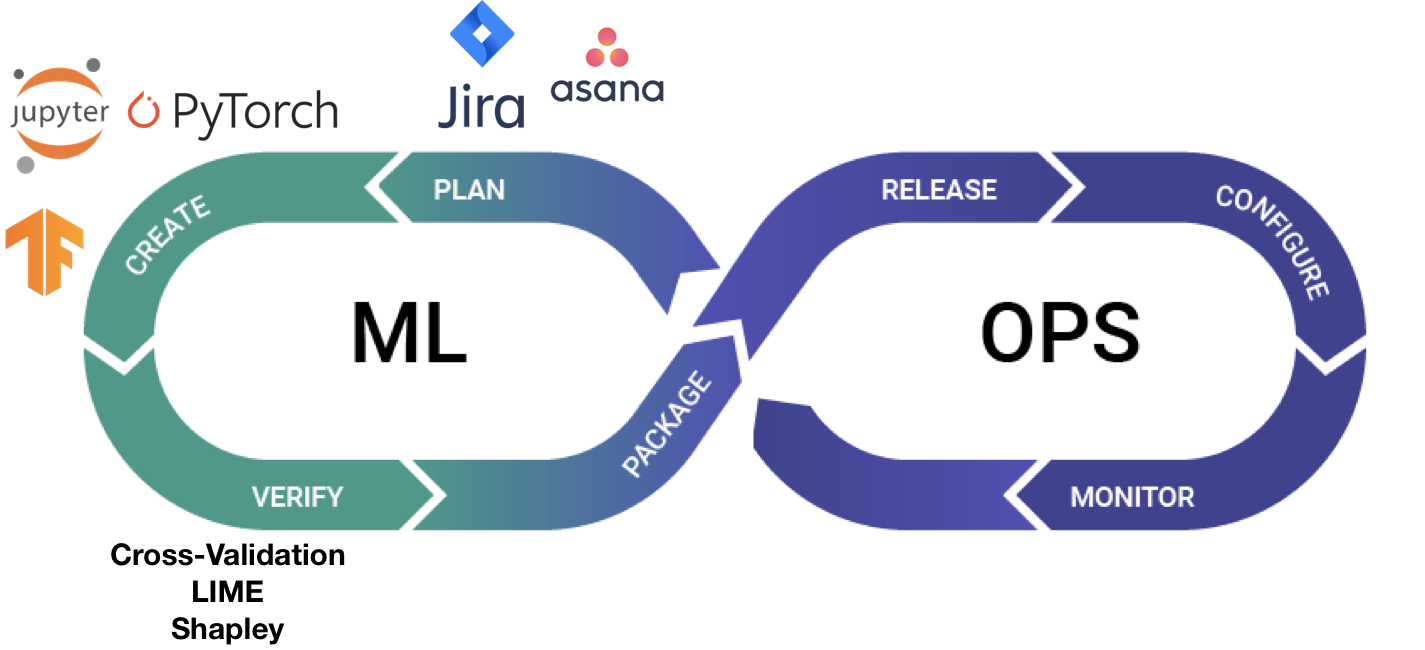
A major shift change in the software landscape from the last decade was the rise of DevOps: a new discipline and a robust set of tools to deliver software products faster and more reliably. The loop below is often used to talk about DevOps and its steps, namely: Planning a software product or feature, Creating or developing it, Verifying and testing the product, Packaging it so it may run in different environments, Releasing the software product (usually automatically), Configuring and operating the product in a production environment, and Monitoring it to ensure that it works as expected.
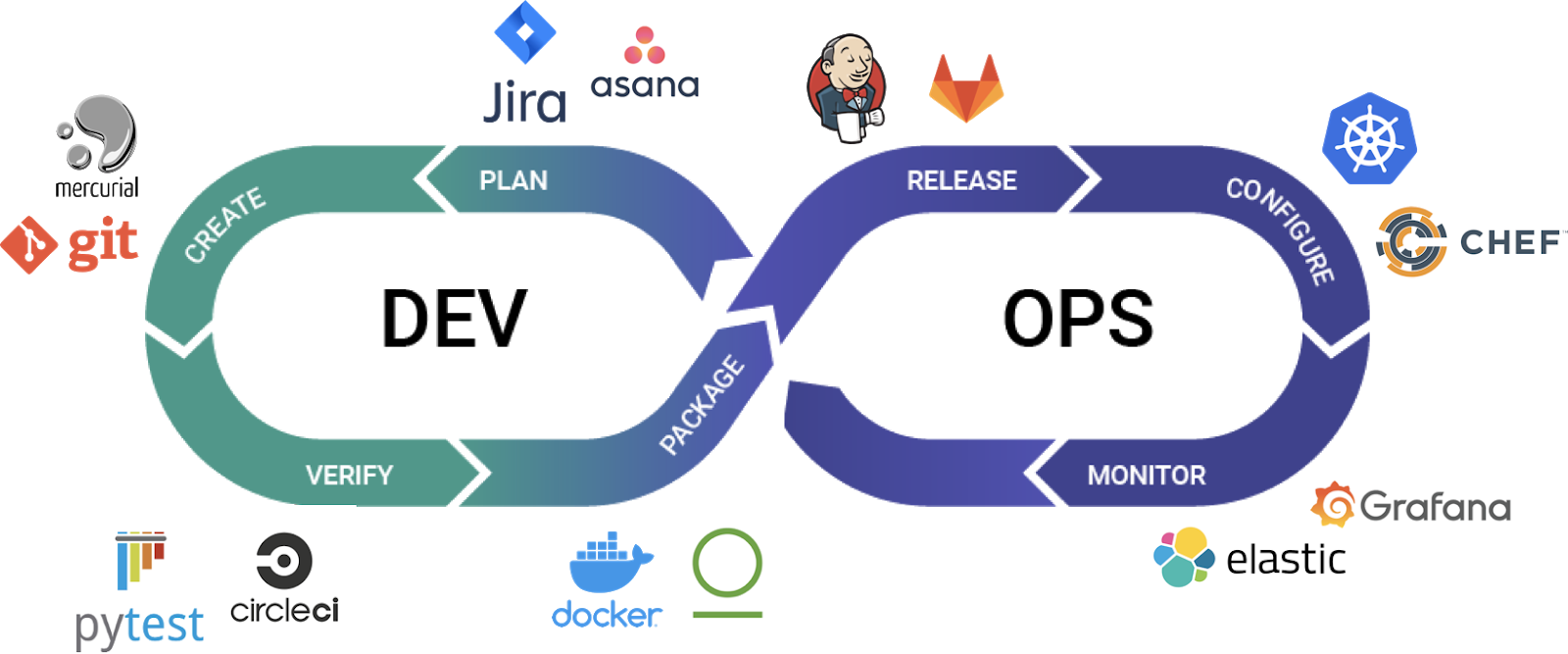
A fantastic set of tools ranging from JIRA for planning to Git and IDEs for creation, to Docker for packaging, to Jenkins for release, and Prometheus/Grafana for monitoring have been built and now run every billion dollar software business.
ML is no different. As ML gets integrated into products, we need a similar stack to enable the rapid and reliable delivery of ML products.
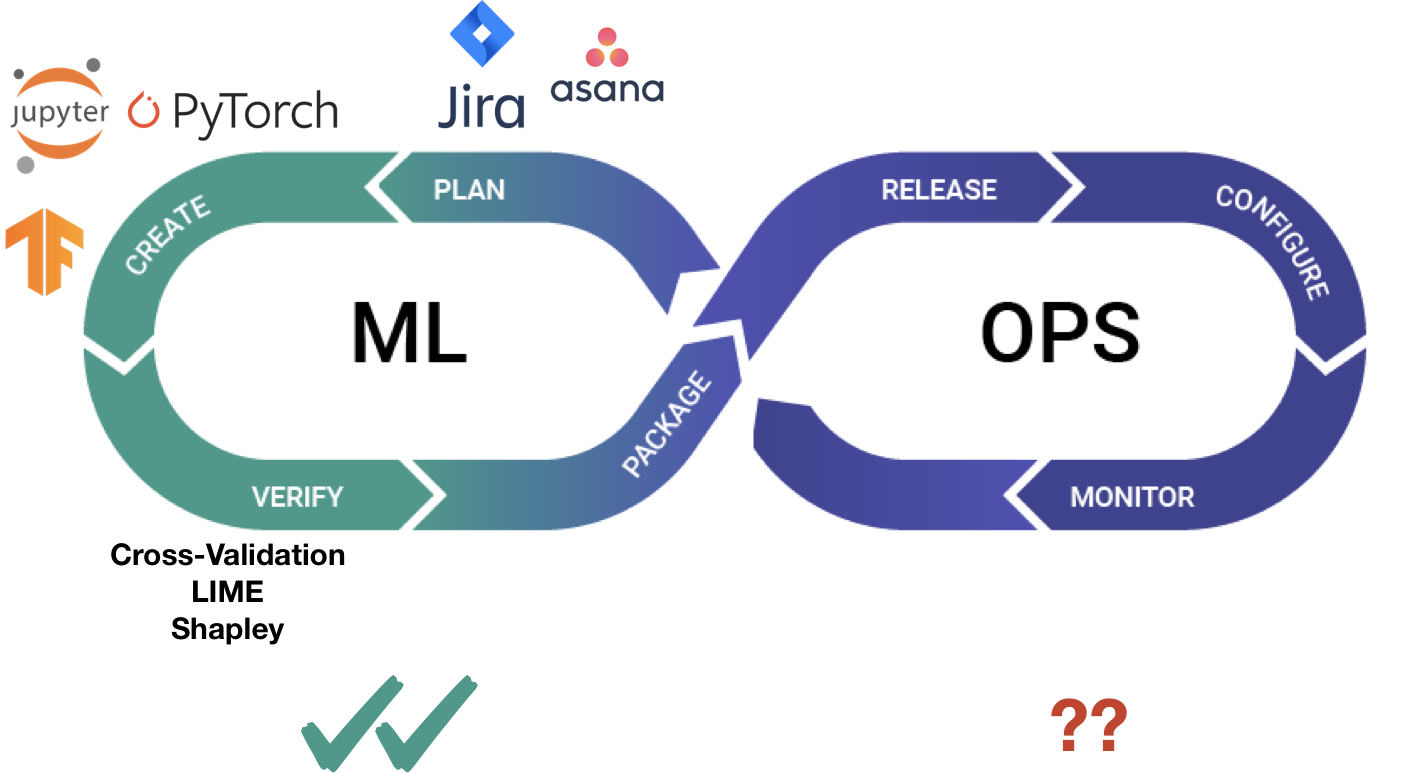
Therefore, in my talk, I discuss how existing, open-source DevOps technologies can be adapted to address the unique requirements presented by ML and ML products.
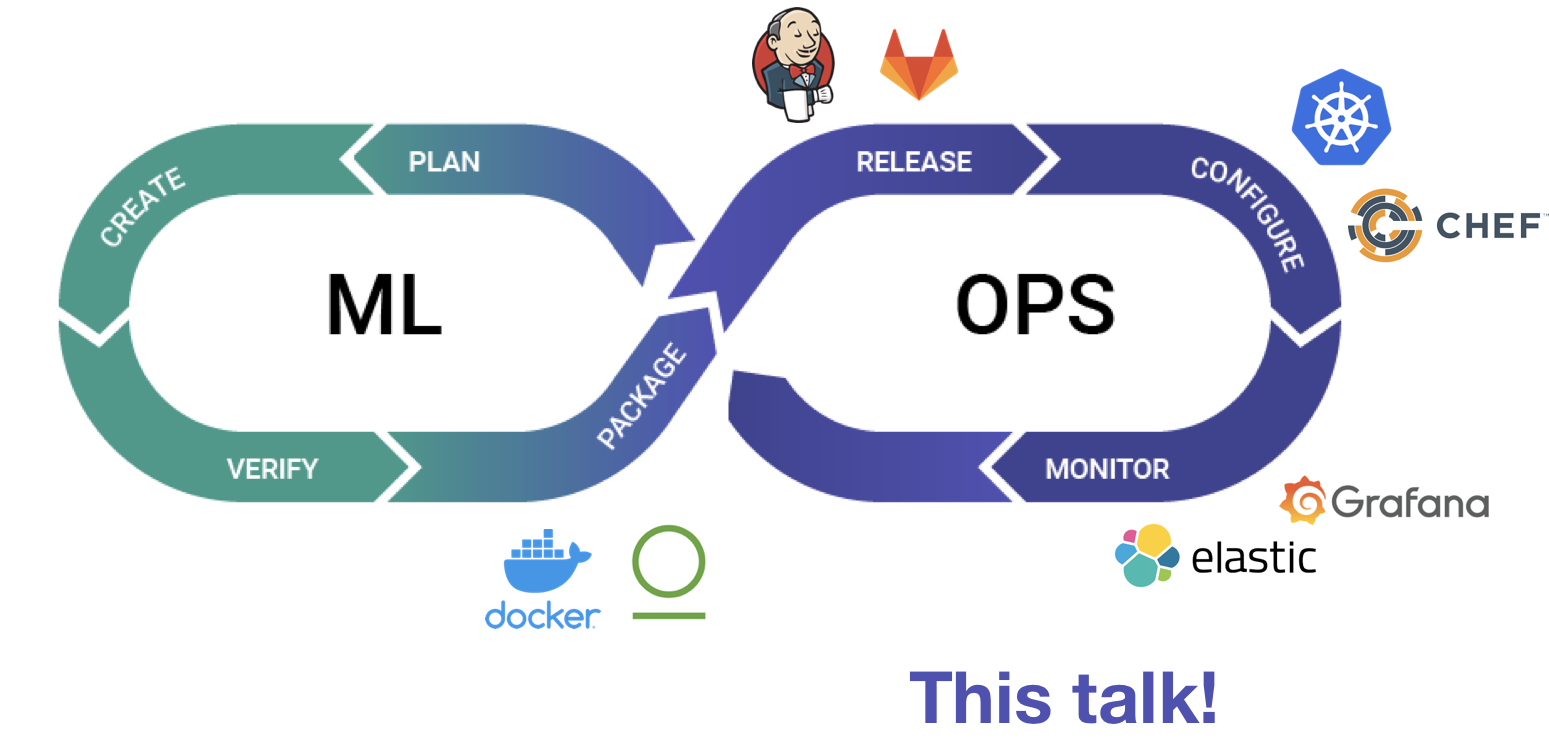
Let’s build an MLOps Pipeline!
Running Example:
Consider a fictitious company, TweetTrader that performs analytics on Tweets to predict movements in the stock market and make trades for their subscribers. A part of their product is the development and deployment of NLP models that analyze Tweets and the operationalization of these models will be our focus.
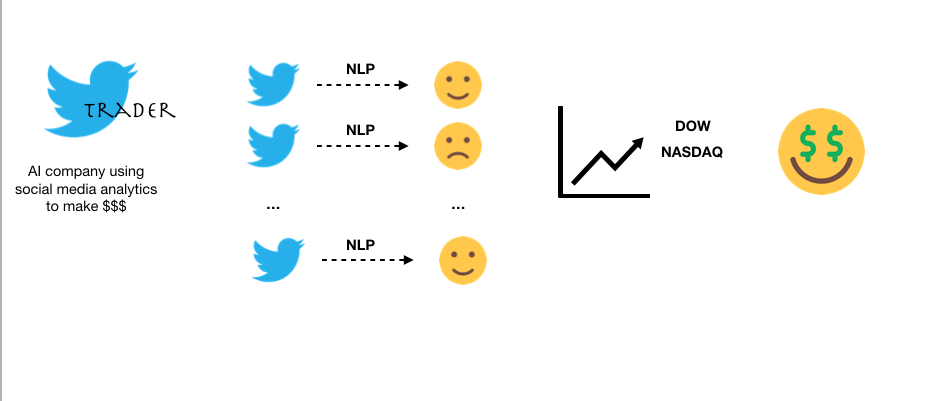
A Simple MLOps Pipeline
Revisiting the MLOps Loop above, we find that there are a few different stages of the MLOps cycle that we must address:
- Packaging the model from an ML library format into something widely usable
- Releasing the model in a repeatable fashion and in the relevant format
- Configuring and Operating the model (not covered in this talk)
- And monitoring the model for system metrics
Because configuration and operations are very tied to the production system (e.g., Kubernetes, what cloud provider, etc.) we will not cover that in the talk.
Since Docker is the most popular technology for packaging and it extends well to accommodate heterogeneous ML environments, we will use Docker for packaging. We will use Jenkins to create a repeatable release pipeline for the model. And we will use Prometheus to monitor system metrics from our model. Since all of these tools are popular devops tools, there are a large number of resources available for learning these tools.
All the code used in this talk is available here.
Step 0: Train an NLP Model for Tweet Classification
In the TweetTrader scenario, our goal is to build a model that classifies Tweets as being positive or negative. There are a number of pre-trained models as well as different architectures we can use for this purpose.
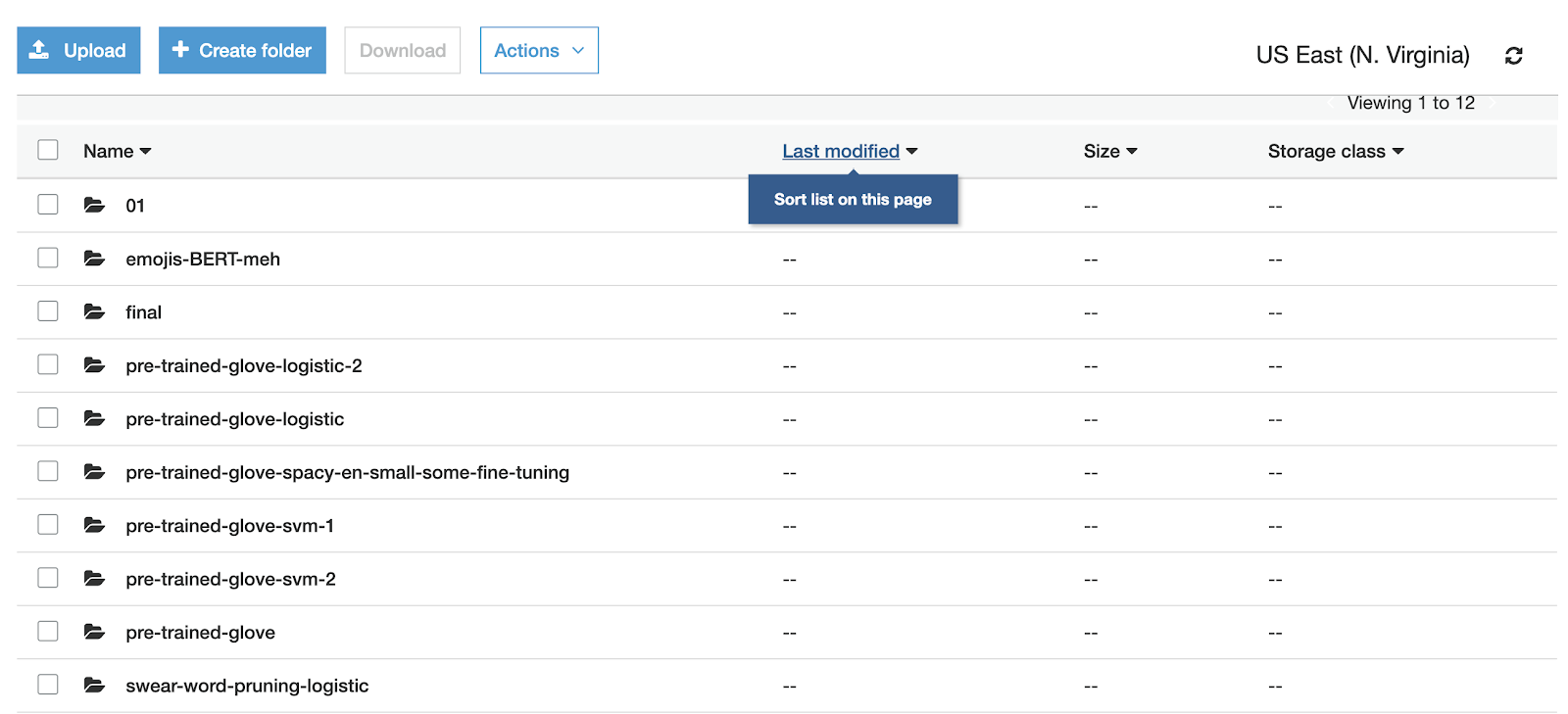
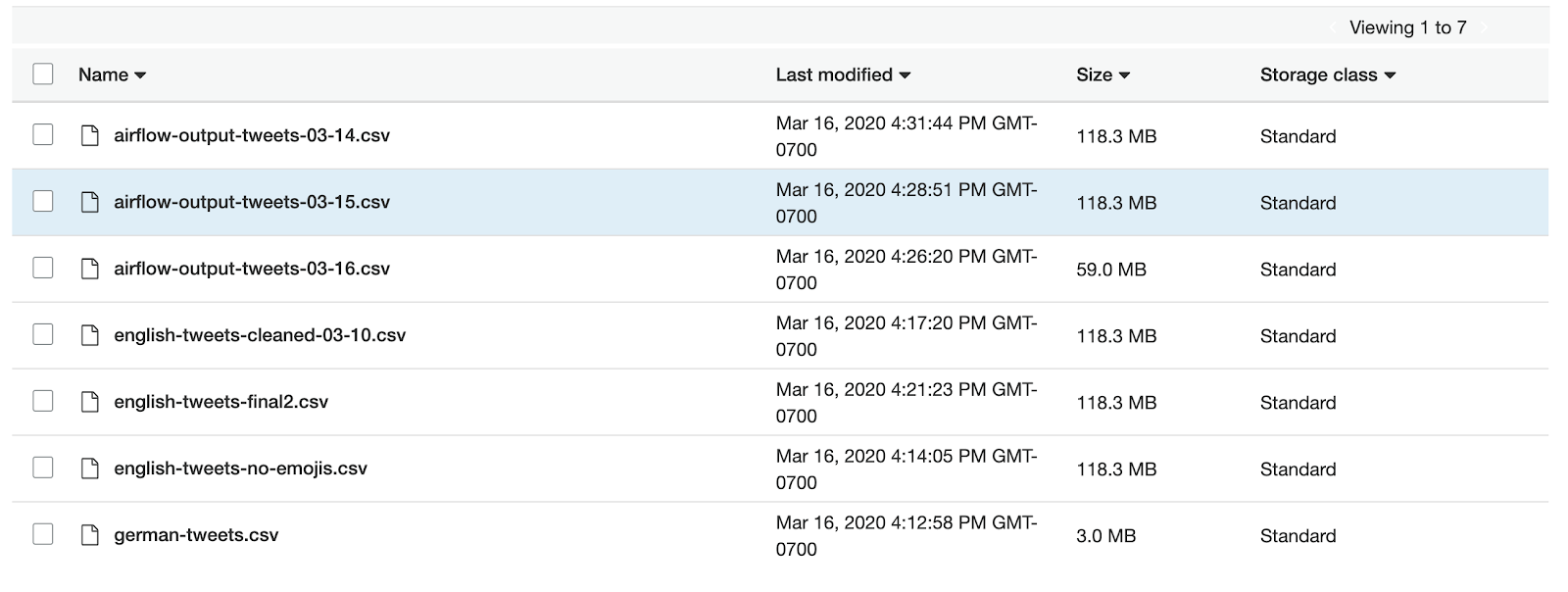
We have gone ahead and experimented with a number of models (e.g., TF-IDF, word embeddings, topic modeling) and different pre-processing strategies for the data itself (e.g., remove emojis, different sentence lengths). Each resulting model is stored in our S3 bucket as shown below.
Step 1: Package a Trained Model
Now that we have a model we want to deploy, we will go ahead and build the scaffolding to package the model. In this case, we will simply put the model behind a flask web server and write a Dockerfile that will dockerize our flask server. The web server will fetch the model files from S3 and serve requests over REST calls.
This is a fairly typical setup and easy to accomplish as shown here. In addition, we make one key change to a vanilla web server: we add instrumentation for Prometheus to collect metrics. In this case, we are exposing the number of requests and the latency of requests.

Ref: https://github.com/VertaAI/modeldb/blob/master/demos/webinar-2020-5-6/01-ad_hoc/02-package/predictor.py
Lastly, we also write logs to a log file to aid in model debugging.
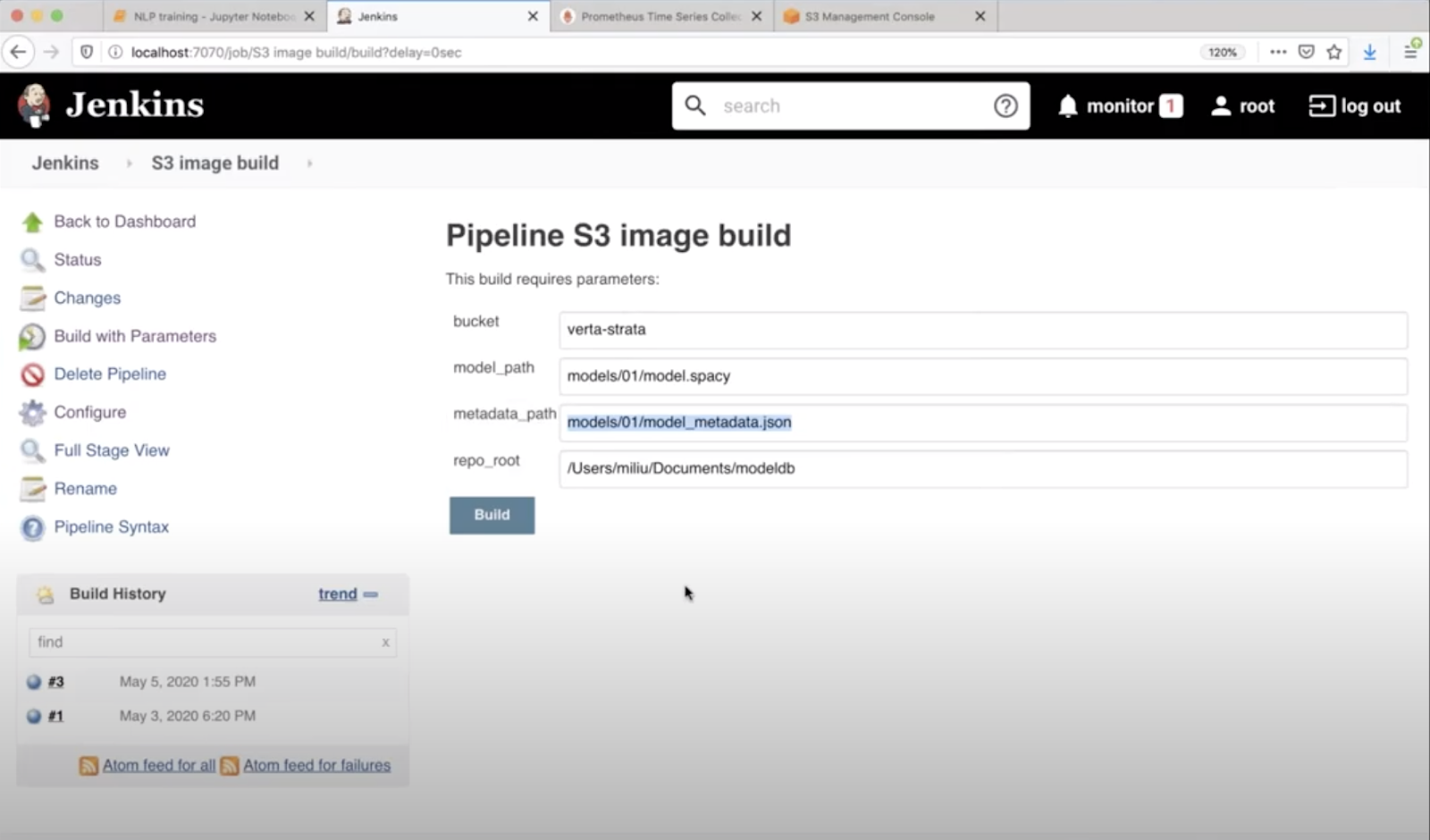
Step 2: Build a Release Pipeline
Next, we automate the building of the inference server so that every time we have a new and updated model, we can just click a button and have it released into the production environment. For this purpose, we use Jenkins. Our Jenkins pipeline takes as input an S3 path and creates a Docker container that can be stored back to S3.
Step 3: Run the Model
For simplicity, we will run our model via Docker compose. In a real-world setting, this would be done in a Kubernetes environment. In our Docker compose file, we have only two containers -- the model container and the Prometheus container.
We can run docker-compose and spin up our system serving the NLP model.
Let’s make some requests against it!

But wait, what happens in the real world?
Real-World Simulations
Our pipeline looks pretty solid in principle, so let’s put it to the test. We will consider two scenarios here:
Scenario 1: Our new Tweet Traffic is in German
Looks like Germany has locked down their borders and banned groups of more than 2! Suddenly our traffic has a lot of German language words, and our models can’t handle them.
We look into our logs and find that our model is mis-classifying even the most basic of German phrases. “Guten Morgen” (Good morning) is being classified as negative and so is “Guten Tag” (Good day).

That’s totally throwing off our models and TweetTrader is losing money.
As good data scientists, we know how to fix the problem: we need to use a language model able to handle English as well as German. We will use the Spacy multi-lingual model and extend our training data to also include German tweets. Easy. In principle.
First step, we go and find how we built the current model; i.e., what scripts were used, what version of the pre-processed data, and what hyperparams were used. But wait..which one of these created the final model again?
Which Notebook?
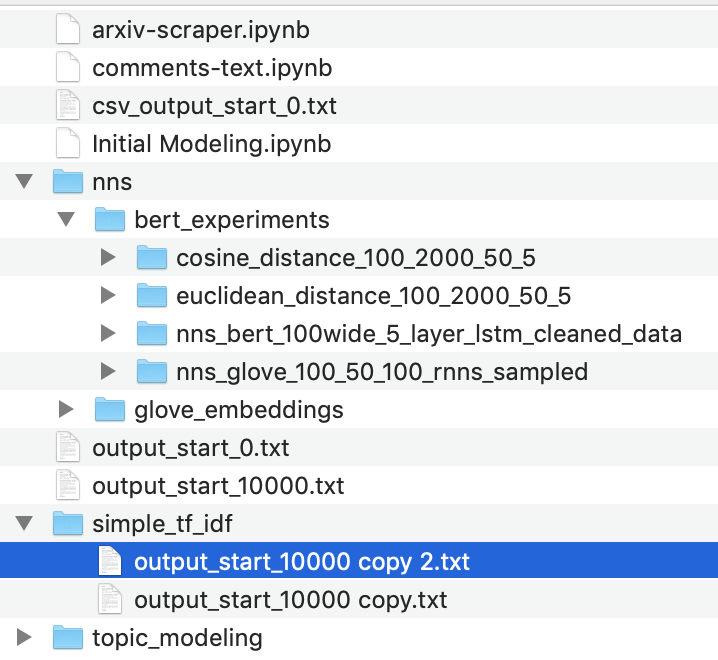 Which dataset?
Which dataset?
Which model?
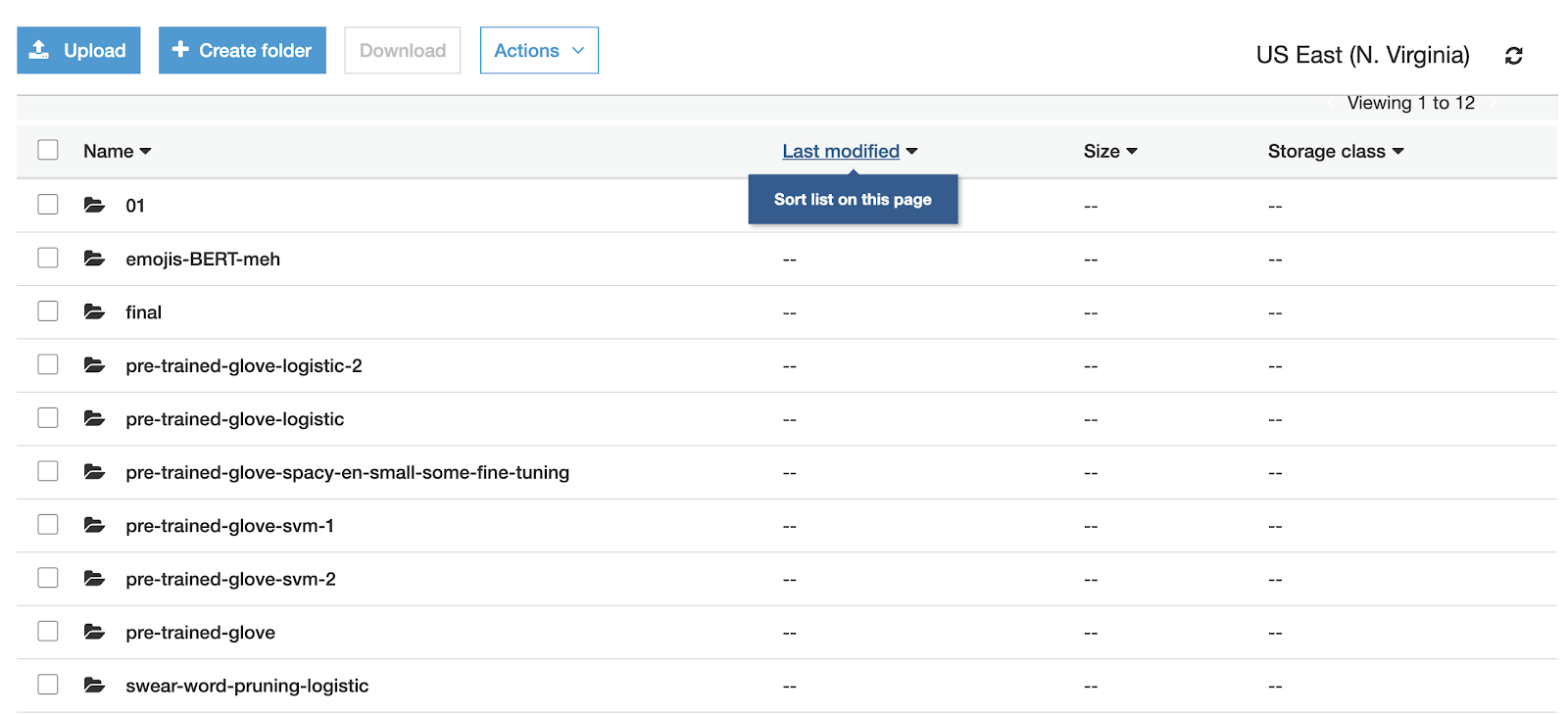
And good luck if you weren’t the person who built this model in the first place. Clearly this is a bad state.
Let’s consider a different scenario -- something more mundane.
Scenario 2: My colleague has a better model architecture but I have really good pre-processing
Suppose your colleague has been working on an amazing new model architecture that gives 5 points improvement on benchmarks. You want to incorporate that into your model training pipeline that uses a lot of peculiar pre-processing logic. How do you combine your work into a cohesive whole? In code, we just make a PR and merge the changes. How does it work with models and Jupyter and data files on S3? A quick look at the pictures above and we know this process will be error-prone.
What’s missing?
If we consider equivalents to the above problems but with regular software, we see that we resolve them all the time (e.g., a DB schema changed? No problem, you can update your code, apply a patch. You and a colleague are working on the same feature? That’s why we invented git!) Crucially, what is missing in the stack, is actually something that is traditionally on the Dev side of the DevOps loop -- our version control system.
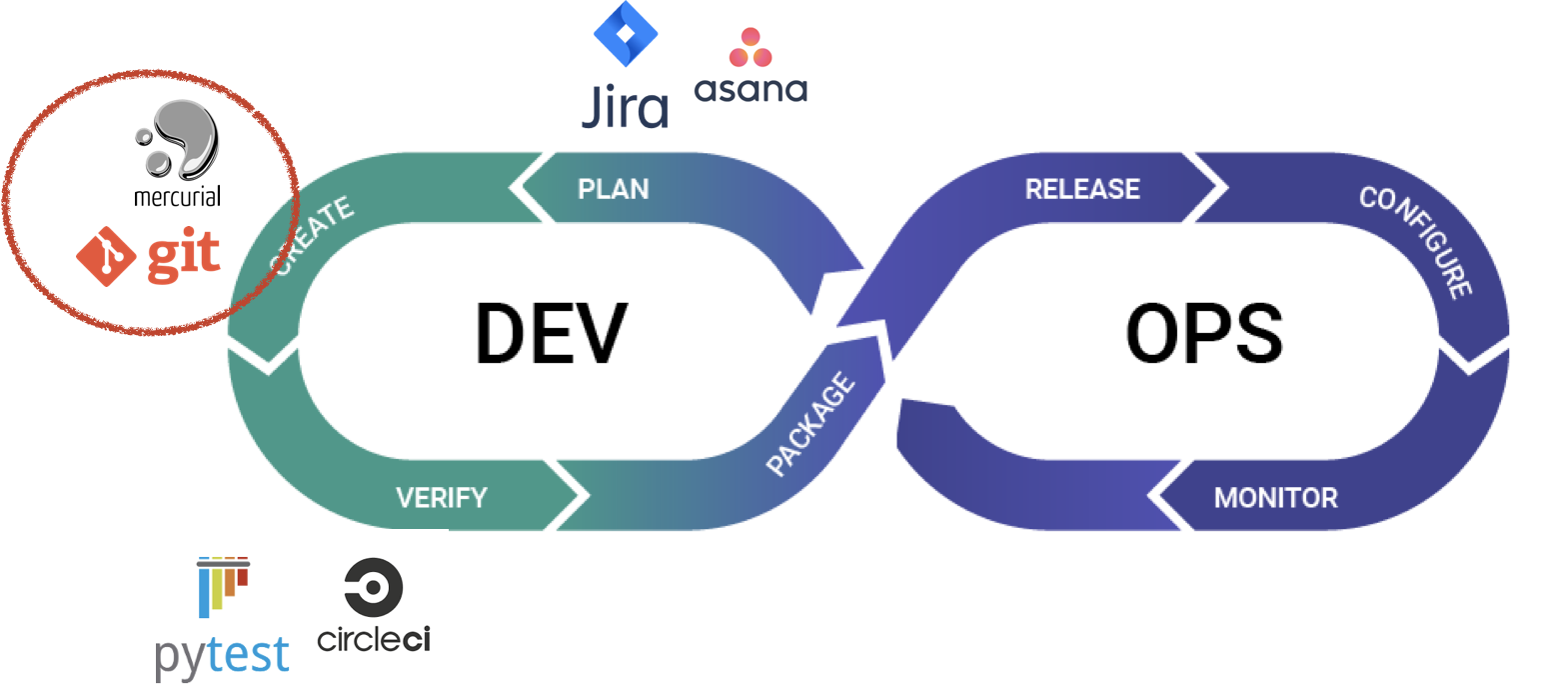
While software development has robust version control systems, ML doesn’t. If there is a production incident in regular software, we can quickly look up the version of a code deployed (e.g., the container SHA) and then in one click go to our Git repository and look up that code SHA. In ML, if there is a production incident, there is no easy way to pinpoint the root cause and even if there is, it’s impossible to quickly remedy it.
As a result, what we need is a purpose-built system for model versioning that takes into account the unique constraints and definitions of models. In particular:
- Uniquely identifies a model
- Enables user to go back in time and fully recreate a model (i.e., stores all the ingredients to re-create a model)
- Allows regular Git-type operations: branching, merging, diffs.
- Provides a way to integrate directly into the ML workflow
ModelDB: a purpose-built model-versioning system
During my Ph.D. at MIT, I built ModelDB, the first open-source model management system. At the time, it was focused on model metadata collection and management (e.g., metrics, tags, hyperparameters). However, having helped dozens of companies operationalize their models, I realized that metadata, while useful, was inadequate. And so, at Verta.ai, we built and released ModelDB 2.0; an open-source model versioning system -- very much like Git, but focused on models and the special considerations that come with that. So what does that mean?
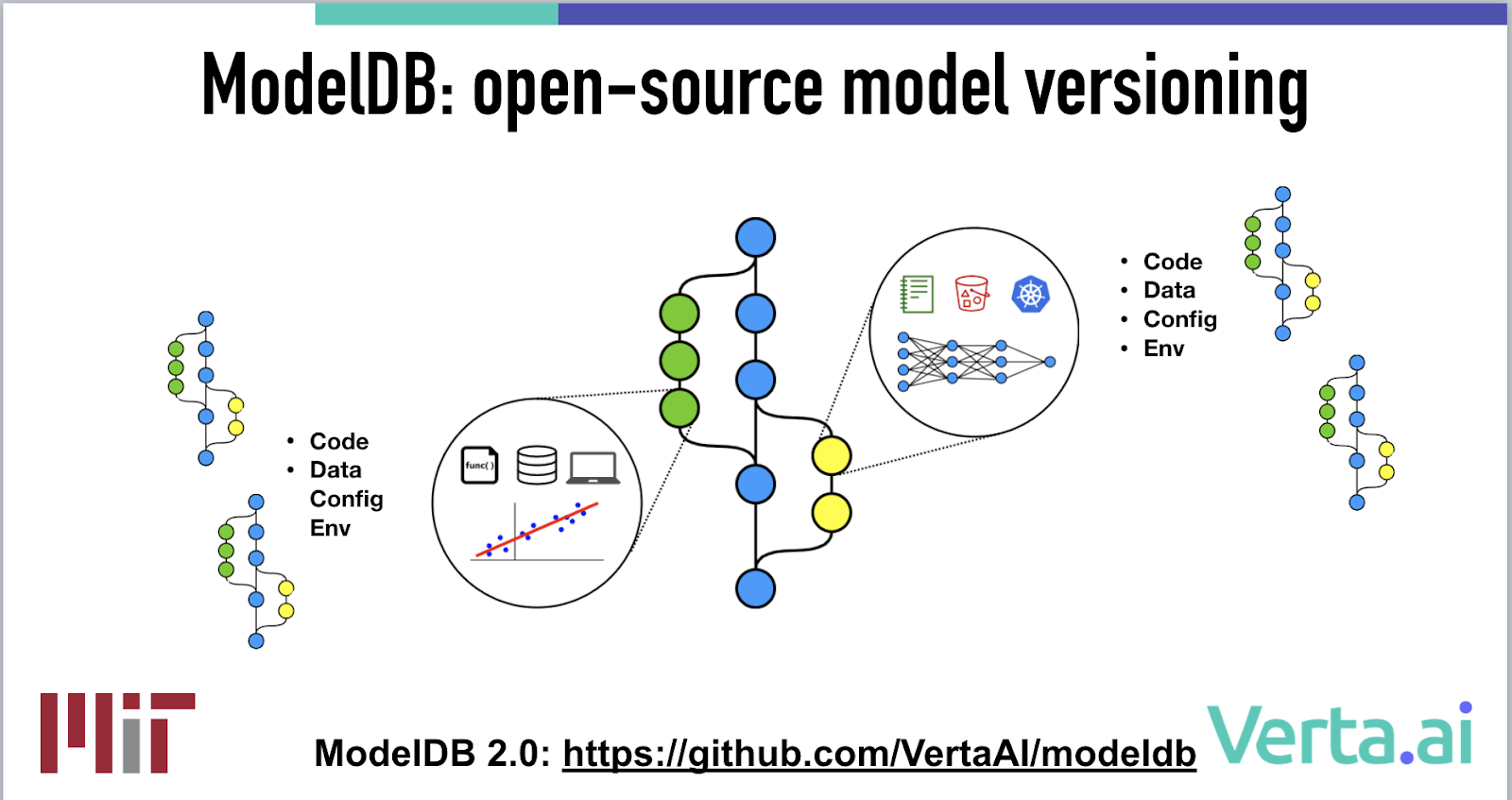
Briefly:
- ModelDB versions the ingredients required to recreate your model, namely your code, data, configuration and environment.
- Each model is uniquely identified by a commit SHA (very similar to Git) that in-turn has versioning information for the 4 ingredients defined above. So given a model SHA, you can always recreate it.
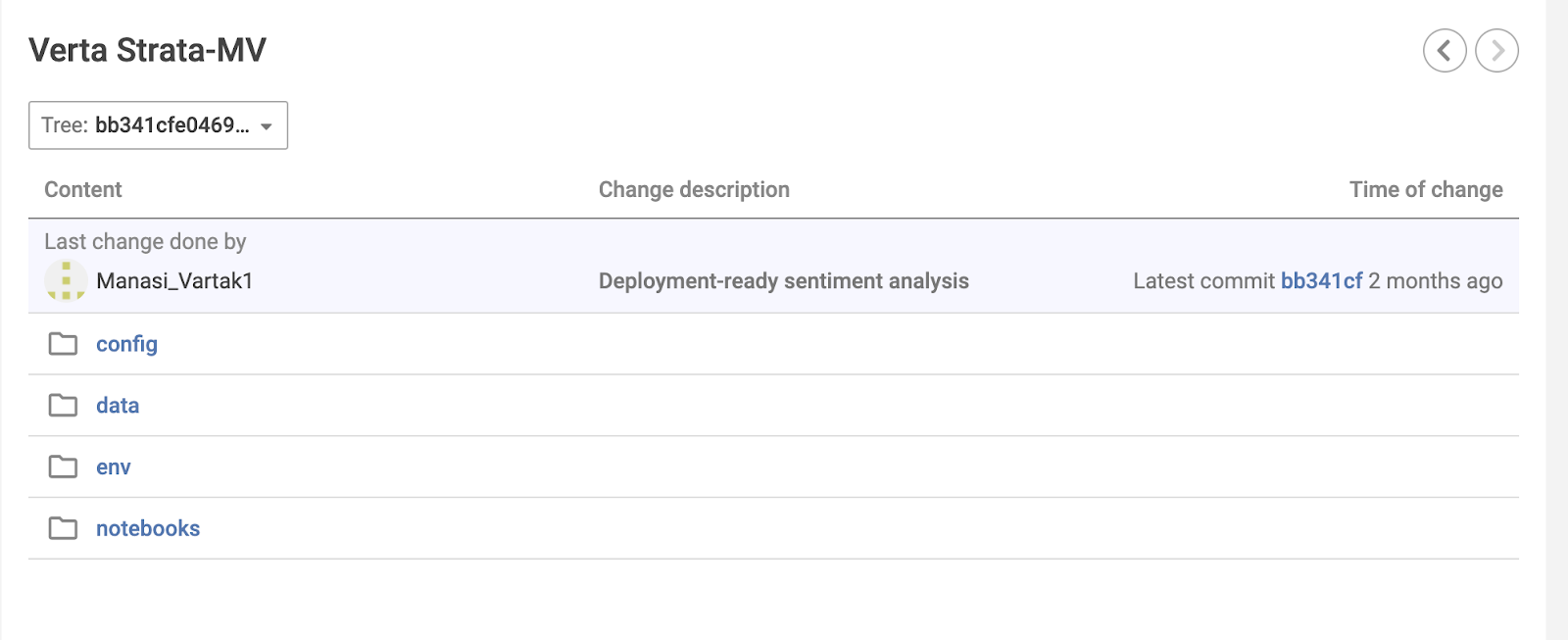
- You use this versioning system as a library and version your models as you are building them. A few lines and you are good to go

- You can use branches, merges, tags as usual as with Git
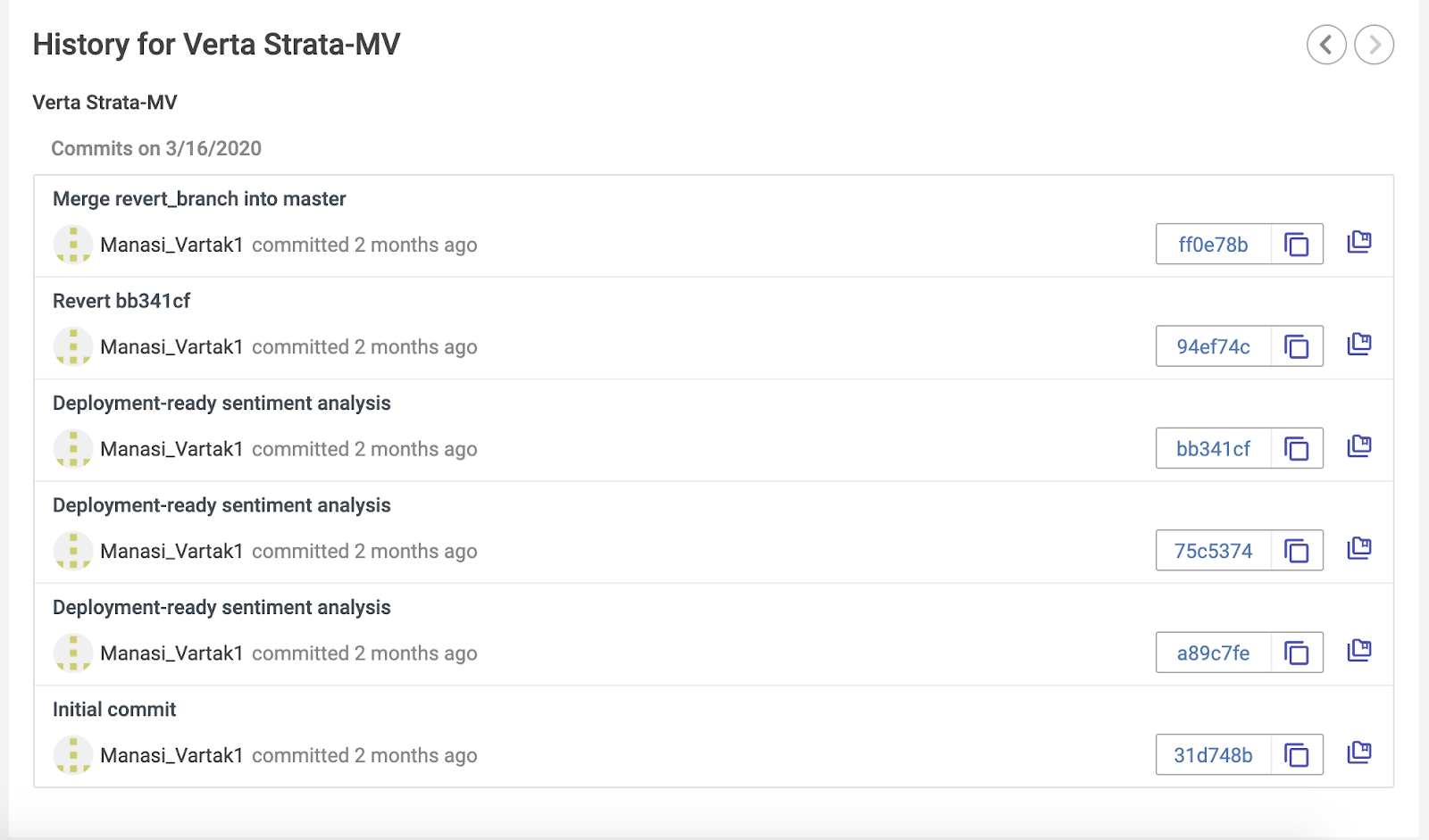
Updating our MLOps Pipeline to use ModelDB
Now suppose we had used a versioning system like ModelDB while building our models in the first place. All this requires is two changes:
- We use the ModelDB library to version models as we’re building them
- In our Jenkins pipeline, instead of taking an S3 location, we take our commit SHA and build a model from it.
- That’s it!
Revisiting our Real-World Simulations
So how do we fare in our real-world simulations from before?
First off, each of our models have unique IDs now (our commit SHAs). Each of these SHAs is associated with all the information to recreate a model.
Scenario 1: Our new Tweet Traffic is in German
As before, we need to update our model to use the multi-lingual model and use the correct datasets. Unlike before, we simply see what version of the model is deployed, find the commit SHA for the model and simply navigate to ModelDB to see all the ingredients for the model.
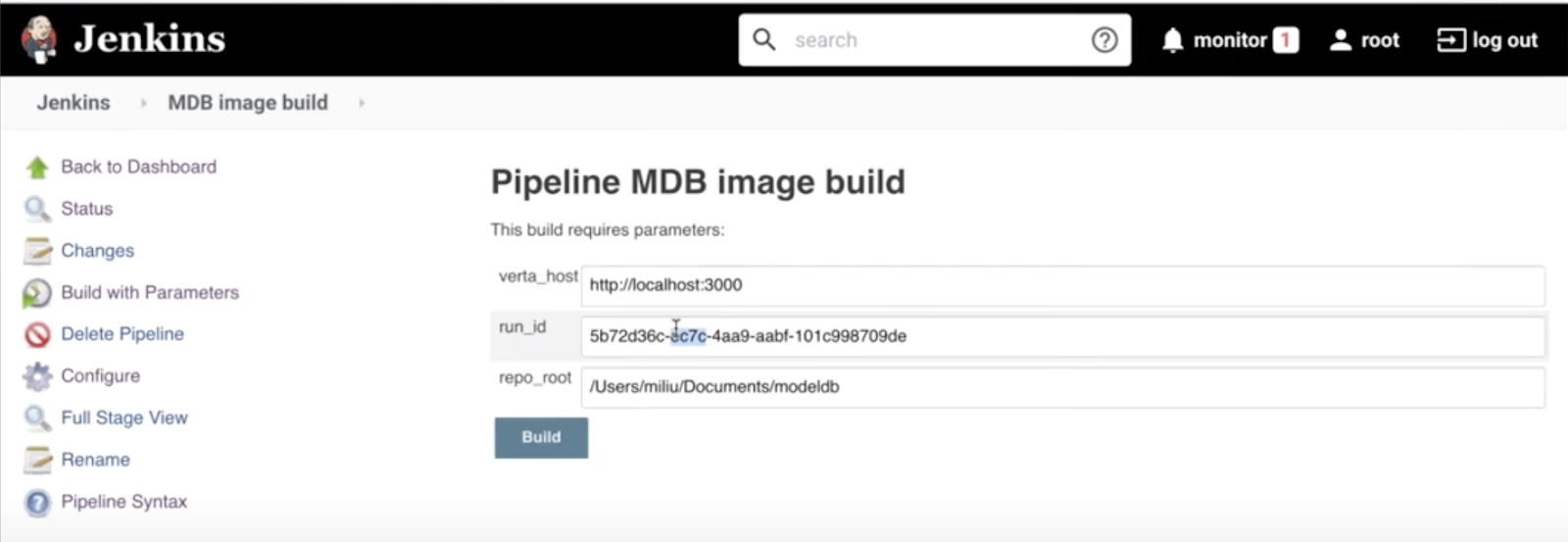
From here, we can create a branch from the committ, make our updates and ultimately merge into master. No sleep lost over how to get the right Jupyter notebook to re-create the model.
Scenario 2: My colleague has a better model architecture but I have really good pre-processing
With a versioning system like ModelDB, this is no different from working with Git. We have two branches with different changes. So we diff them, we merge them (resolving conflicts as required) and that’s it, we now have a branch with both changes!
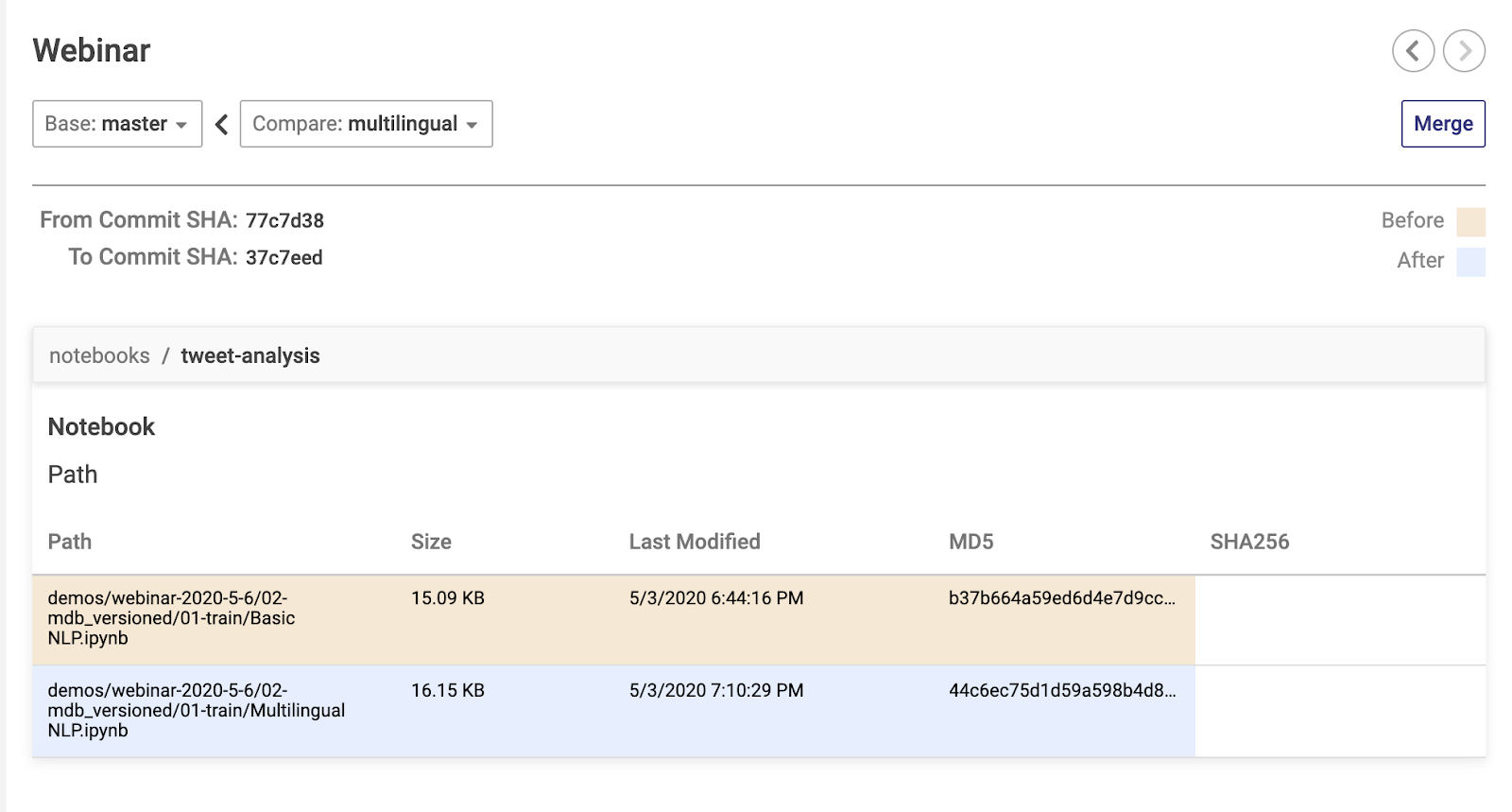 It’s amazing how much a simple change like a versioning system can do for MLOps. A few lines and all systems are more reliable.
It’s amazing how much a simple change like a versioning system can do for MLOps. A few lines and all systems are more reliable.That’s a wrap!
So that’s it! We covered a lot of ground including what’s MLOps, building MLOps Pipeline with open-source, and the importance of version control. If you were to take away three key things from this talk, let them be the following:
- MLOps is DevOps for ML: it helps you ship ML products faster
- Model Versioning is to MLOps what Git is to DevOps. You can’t live without it
- You can build a very robust MLOps with open-source: ModelDB, Docker, Jenkins, and Prometheus
This is just the beginning of the conversation! Join us on Slack.
About Verta:
Verta builds software for the full ML model lifecycle starting with model versioning, to model deployment and monitoring, all tied together with collaboration capabilities so your AI & ML teams can move fast without breaking things. We are a spin-out of MIT CSAIL where we built ModelDB, one of the first open-source model management systems.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


