
In my last post, I introduced Model Catalog, Verta’s enterprise model management system. In this post, I’m going to dive deeper into the information about each model version that is contained in Model Catalog. The versions of your model are the discrete deployable units of the solution you made. If the model you register is the problem you want to solve – i.e., “We need an image moderation model to remove violent gifs” – then the versions are each newly updated and slightly better iteration of the model.
The fact is, we all know that by the time you ship a model, it’s often already stale. So our goal with Verta is to enable and speed up the iterative, cyclical nature of ML model releases. We have customers using Verta and Model Catalog to ship a new version of a model to production roughly every 24 hours — so keeping the information for each version organized is critical to tracking and identifying any issues quickly.
Within Model Catalog, in addition to a summary view, you’ll find three key tabs for each version, with each tab optimized for a slightly different use case and set of people in your organization.
The Release tab helps your team understand if this particular model version is released. If yes, where? And do you have a clear record of its endpoints and deployments? If it hasn’t been released, what’s left to get it out the door?
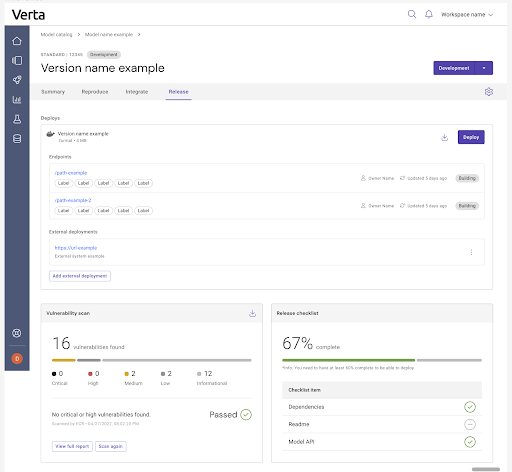
If the version is already released and being served via an endpoint, the Verta endpoint information is listed top and center. This includes the status of the endpoints, their paths and any labels on them. Each endpoint is a live computing resource, so we want to make sure your team isn’t accidentally duplicating deploys. (If only it was that easy to deploy! More of our customers run into this than you’d think.)
Other customers have hybrid deploys, so you can download the containerized version of your model here as well. Whoever downloads the package can leave a note on where the model is actually deployed by logging external deployments (for example, “It’s on the alpha robot hardware” or “We’re running it in Snowflake, ask Dave”). To put it simply, this is the system of record you can actually trust to tell you if and where this model is actually deployed.
On the other hand, if the model is not yet live, our release page helps your team get it released. A customizable release checklist is available so your leaders, governance teams, platform and ops engineers can configure what “release ready” means (more on that coming soon!). Data scientists and engineers can then track each version’s progress to being releasable, check off tasks when they’re done, provide evidence or documentation for any key processes, and so on.
Soon we’ll be adding in the ability to run automated preconfigured Github-like workflows, so model testing suites can be run automatically pre-release. Everything that happens is recorded in the model’s paper trail, so your policy people can rest easy.
We put our vulnerability scanning integration front and center so that your data scientists can quickly detect and remediate any security vulnerabilities with models prior to release. Scanning takes just the click of a button and a few minutes, and then a report and visual are generated, showing how many vulnerabilities were found in the model and its packages. We offer scanning via Amazon’s ECR service or a custom integration with the service of your choice via a webhook.
Once it’s ready to release, or as part of your testing process, the model can be quickly deployed using the Deploy button. You can stand up an endpoint to test from within this page:
As part of the release process, data scientists can document everything needed to reproduce this model version. The Reproduce tab contains all the model metadata related to understanding (and if needed, reproducing) this model version.
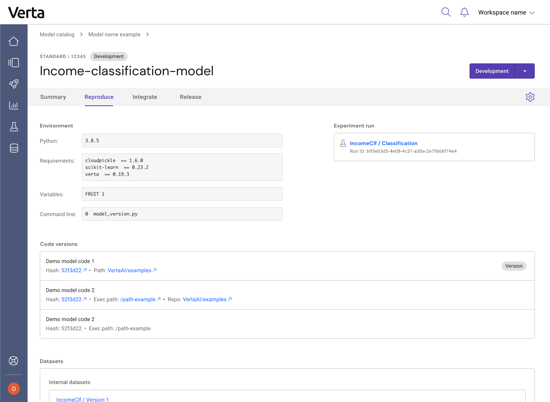
Environment variables that the model needs to run are listed, such as which version of Python or Verta it needs. If the model was registered from an experiment that was tracked in Verta, a quick-link sends you to the experiment tracking page to see all the training details. All code versions can be logged, with direct links to the branch in Github. Datasets used to train or validate the model can be logged and tracked as well.
We also allow your team to log arbitrary metadata on the version, which is very useful if you want to make training data distribution charts to display in the UI or log a confusion matrix based on a golden set of data.
The Reproduce page exists as an insurance policy in case a model ever needs to be handed off quickly between team members or reproduced in a hurry; all the pertinent information is available in one centralized place.
The Integrate page has all the information an engineer needs to quickly integrate this model into existing applications and data processing pipelines. Streamlining this process helps get the model version into production faster.
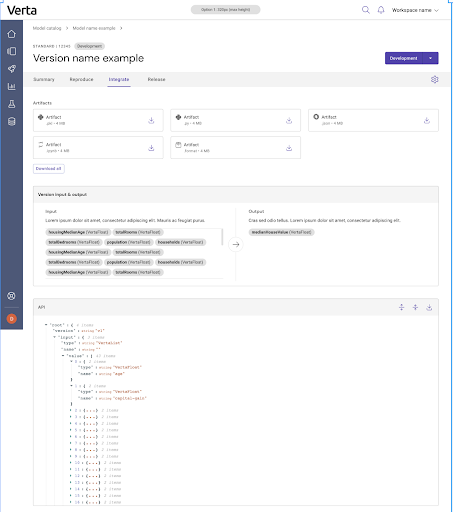
Artifacts for the model are organized and downloadable. The version’s API is documented, with an easy-to-read widget that shows the input and output with space for adding descriptions of the input and output data. The API contract is also shown as JSON, which is easy to download for testing a model’s endpoints or integration.
On Model Promotion
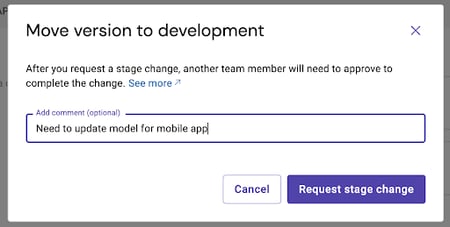
Once the model is ready to advance to production (or staging, or dev), you can promote the version stage and get peer review to confirm it’s ready for release. Whoever requests the promotion can leave a note for their peer (just like a pull request) to get the model stage updated.
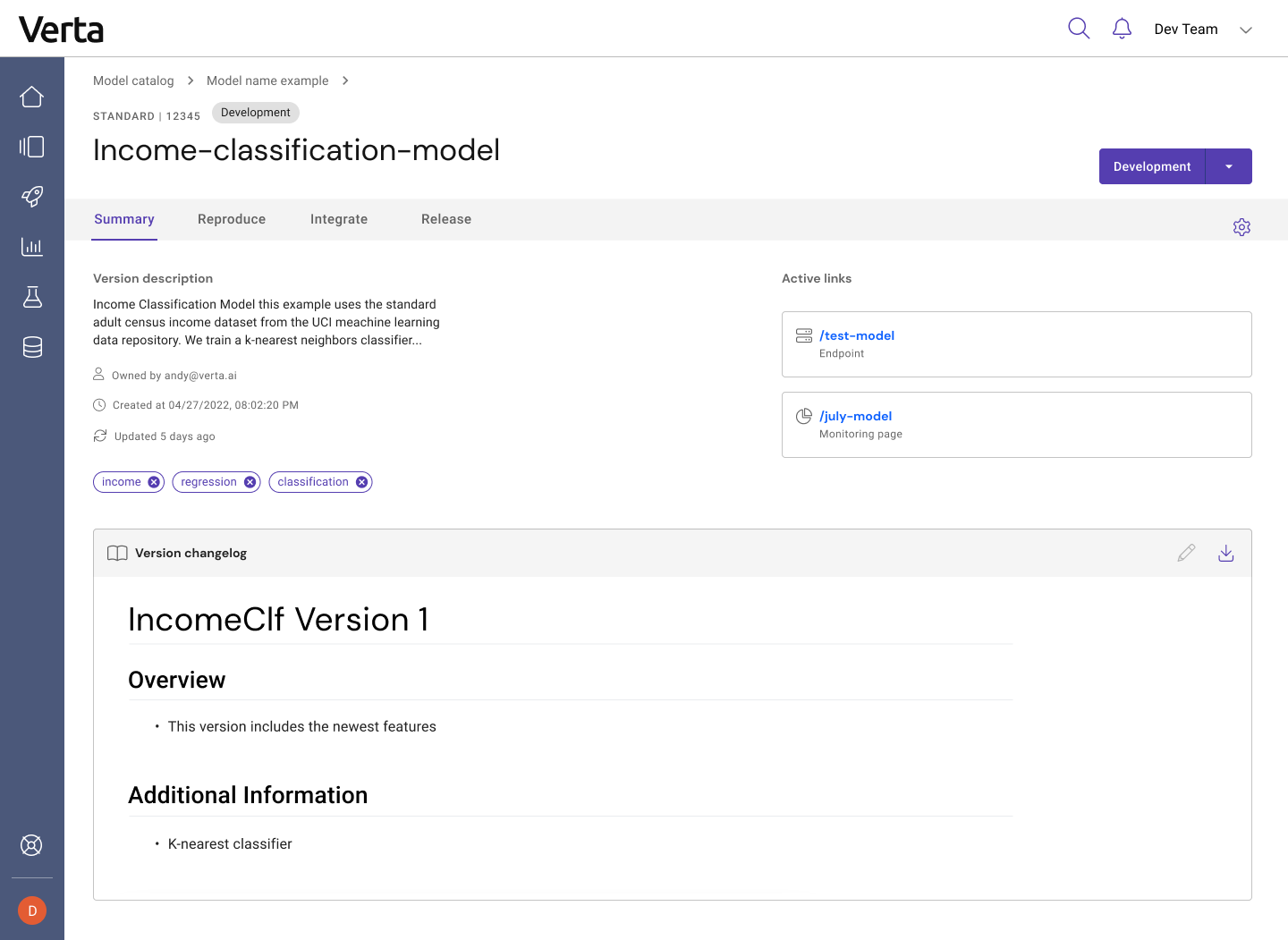
The Summary tab for the version will show any promotion requests with comments, and users with the required permissions can approve or reject the promotion of this version. A brief changelog and description are available for the version so you can track what’s different about this version compared to the previous one(s). The most recent deployment and monitored entity will be linked right from the Summary page, so if you’re looking to test the endpoint auto-scaling or monitor the already-deployed model, you can quickly skip to the right pages and avoid having to dig through the model documentation.
Model Catalog includes quite a number of features, based in part on my own familiarity with the pain of being a product manager chasing a team of data scientists to beg/nag them to fill in a Google doc with basic data about our models. That’s why we made it easy for data scientists to dump the information everyone needs into Catalog via Verta’s Python client and the Jupyter notebooks they know and love. The consumers of that information (engineers, DevOps, product managers, risk managers) can easily find what they need without having to shoulder tap some of the scarcest resources in the company — and the data scientists get to focus on what they do best, creating great data science.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


