
What is a Model Registry?
A model registry is a system that allows data scientists to publish their release-ready models by facilitating the transition from ad-hoc model experimentation to stable deployment.
Verta's Model Registry can be a hosted SaaS service or deployed on-prem or in the cloud. It runs on Kubernetes and supports APIs, client libraries, and a web UI.
Why use a Model Registry?
A production Model Registry addresses the following challenges:
-
No central place to share ready-to-use models
-
Lack of knowledge about how to use them
-
Model release and handoff is ad-hoc, and existing SDLC tools aren't compatible
-
Lack of compliance and safe practices during model release, i.e., who can deploy, approve, access audit logs, and enforce security standards
-
No repeatable and standardized best practices for data scientists to follow, i.e., how to package, test, validate, and ensure model reproducibility
How to use Verta's Model Registry
Below, we'll outline how to use Verta's Model Registry to package, validate, and promote release-ready models and apply safe release and governance practices.
Registering a scikit-learn model in Verta
First, pip install verta client and scikit-learn, import other required libraries, and set up your Verta environment variables (email, dev key, and host).
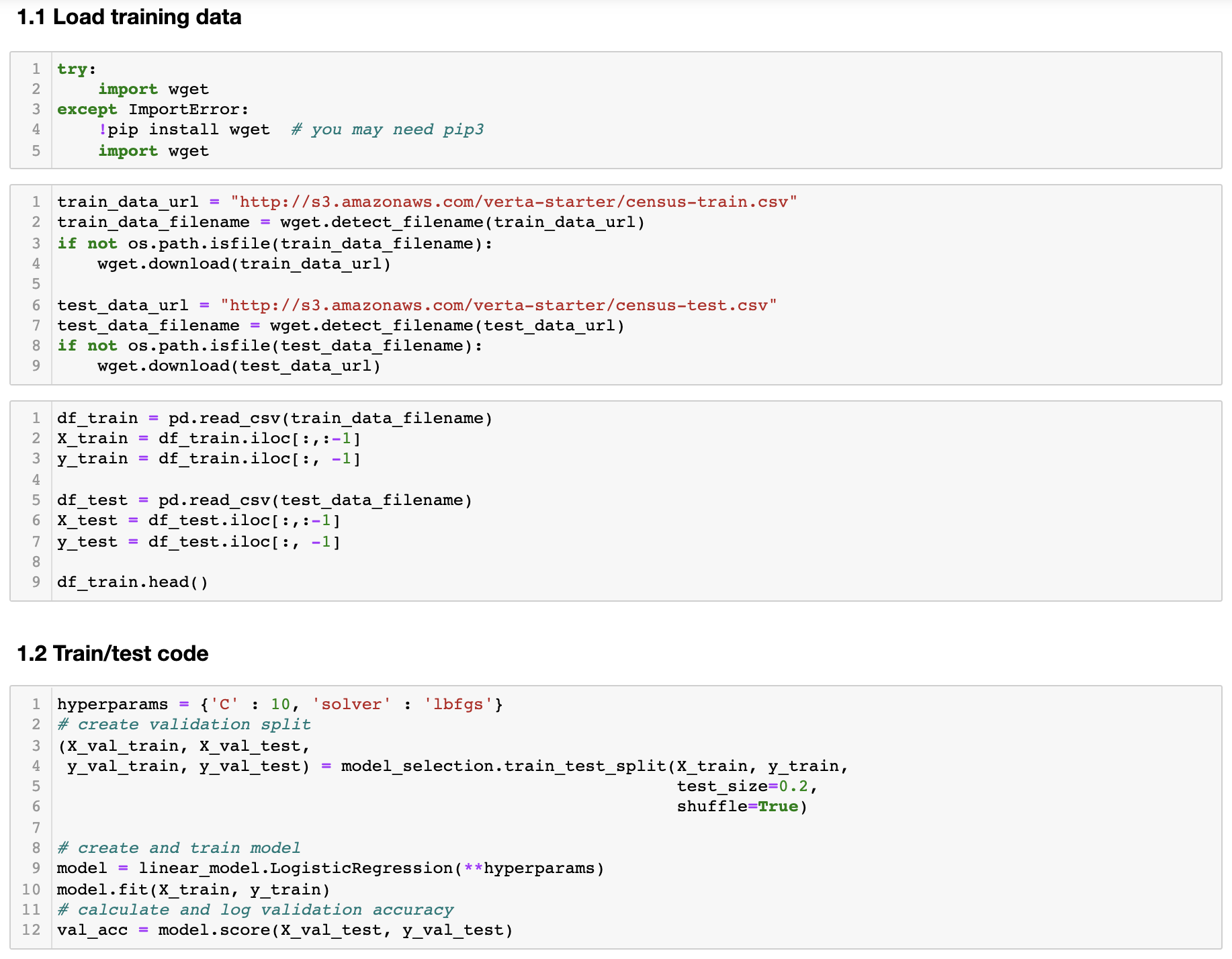
Below is the code to train your scikit-learn model.
Registering a model in Verta
A registered model in Verta has a name, permissions, and metadata (e.g., labels) associated with it. Each registered model can have one or many model versions associated with it.
Below is sample code to register your model and model version.
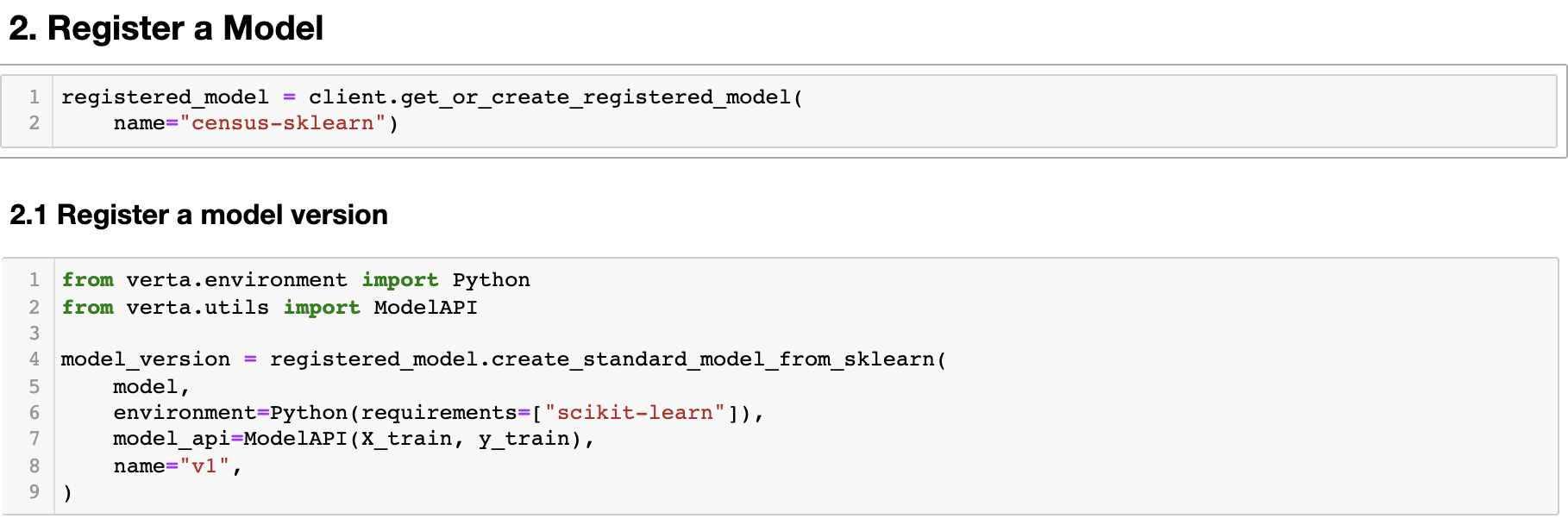
You can use Verta Standard Model specification, bring your custom module, or specify a Docker container to be registered directly in Verta. Registering a model from the Verta Experiment Tracking system allows you to go back to the specific experiment run and get information from the development phase.
Logging model artifacts and attributes
All critical components of a release-ready model are tracked in the registry, allowing for easy access to all stakeholders, including information like training & validation datasets, loss, accuracy metrics, training data distribution, environment dependencies, and code versions.
The example below demonstrates how to log various model attributes, test results, training data distributions, code versions, etc.

Model validation and testing
Verta's Model Registry provides numerous capabilities for model validation & testing:
-
Register datasets (training & test), associate with model versions
-
Use your batch setup or a Jenkins pipeline to run pytests and more complex testing with the registered datasets
-
Verta stores testing output and attributes about your training and test data
-
Compare your development, staging, and production model results before promoting
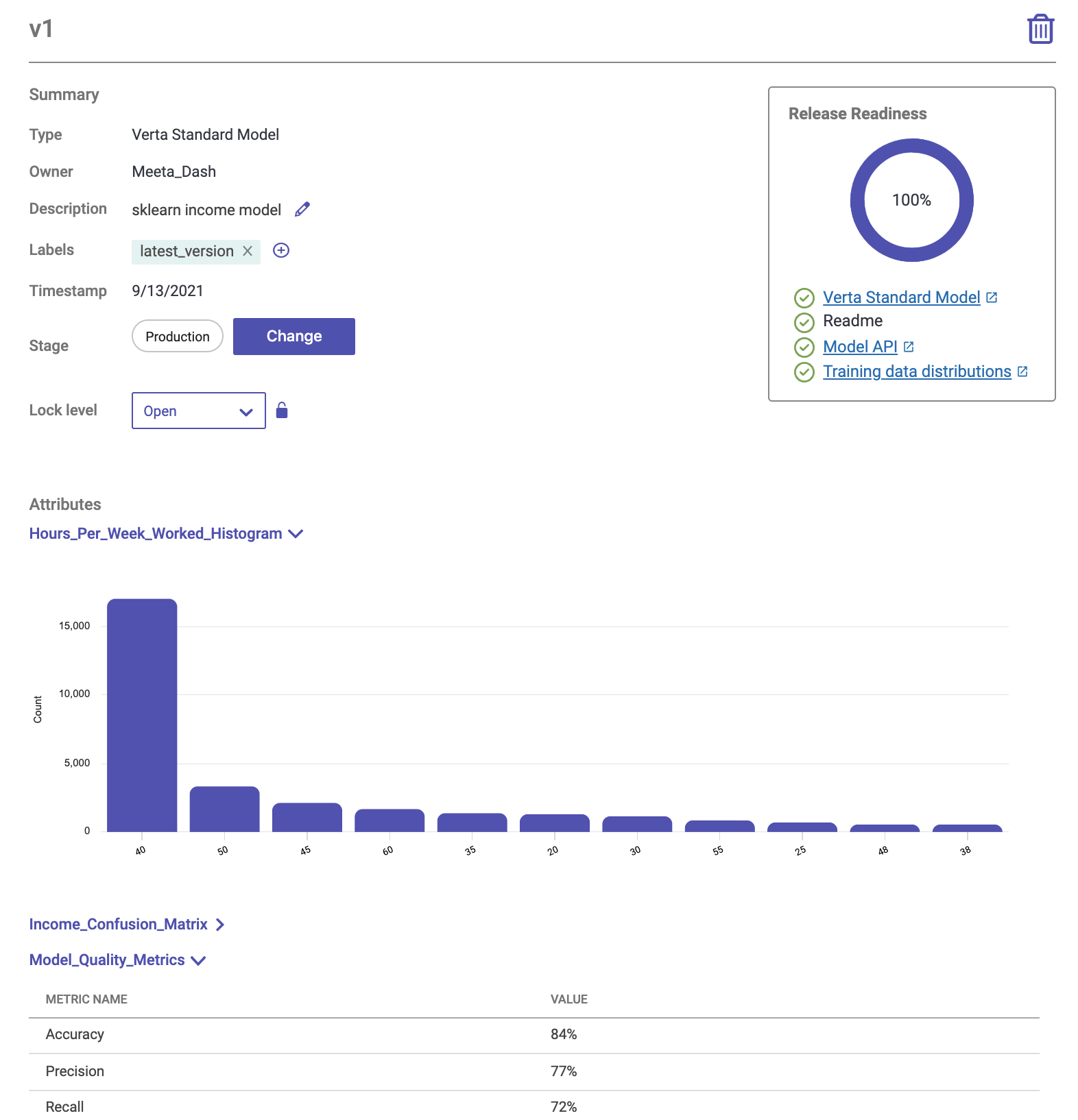
Governance and approval process
In Verta's Model Registry, you can also add approval workflows
-
Not everyone can approve a stage change or deploy a model
-
Activities are logged, providing signals and tracking for updates and promotions across development stages
-
Moving models through different stages will alert those in charge of these requests, which results in gradual and observable promotions.
You can also layer in additional compliance measures by adding lock levels that guarantee model immutability and avoid accidental updates to production models.
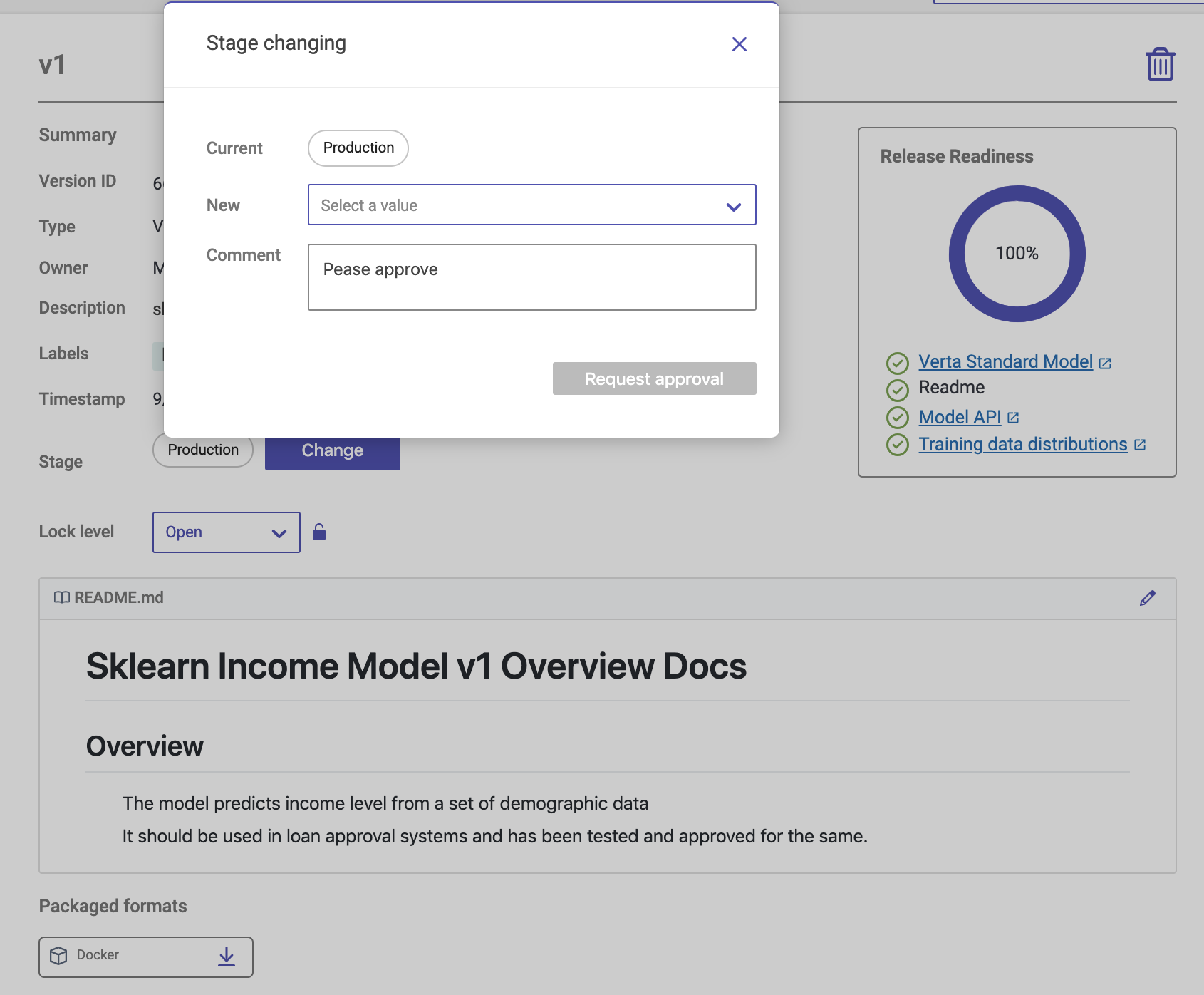
Below is example code to fetch a model version after it is promoted to a specific stage and then deploy it.

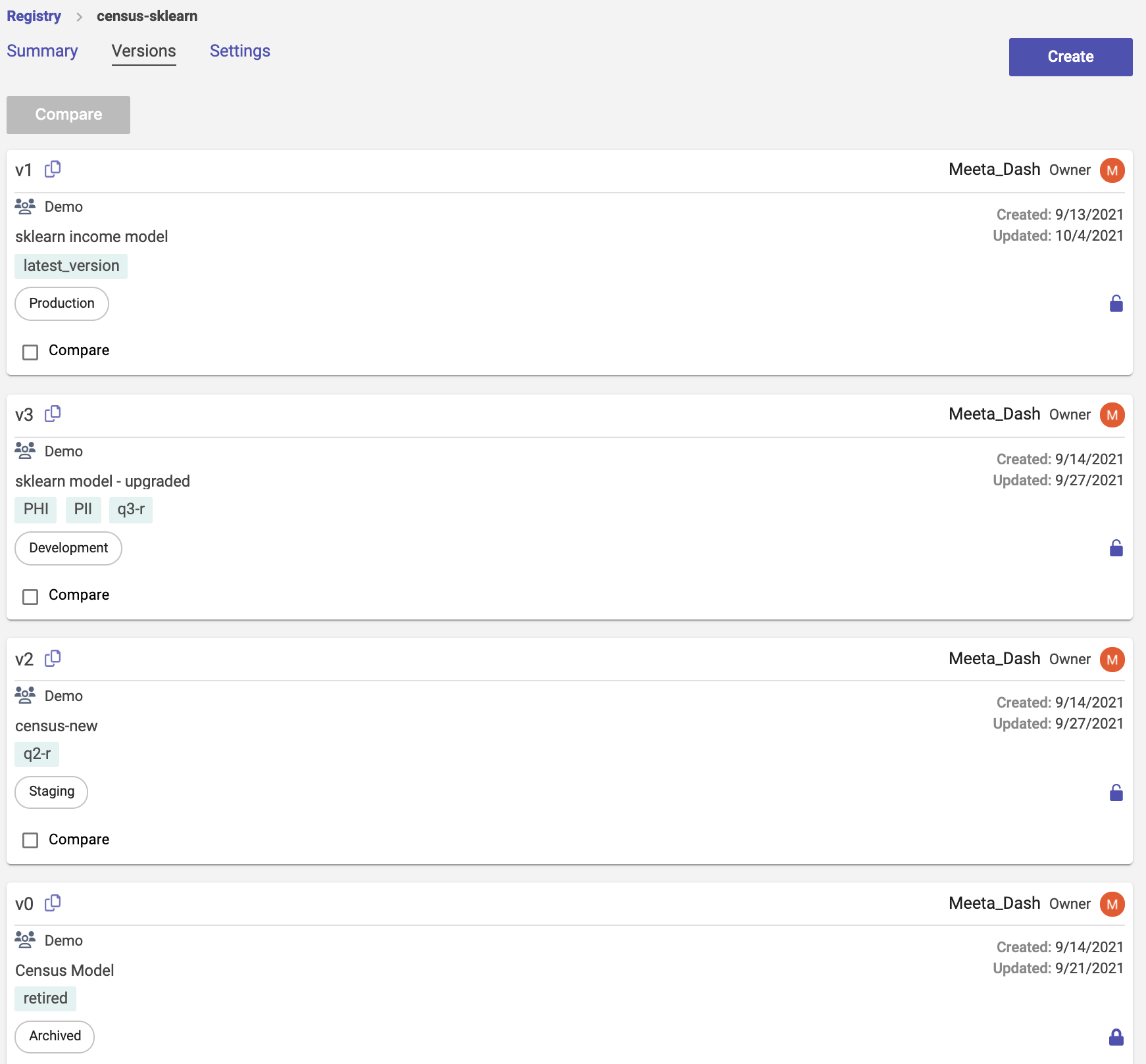
Model inventory for transparency and visibility
Verta's Model Registry is the single source of truth that serves as the inventory for all available models. It tracks all the critical information about the model and its lifecycle, including Model ID, description, tags, documentation, model versions, release stage, artifacts, model metadata, and more.
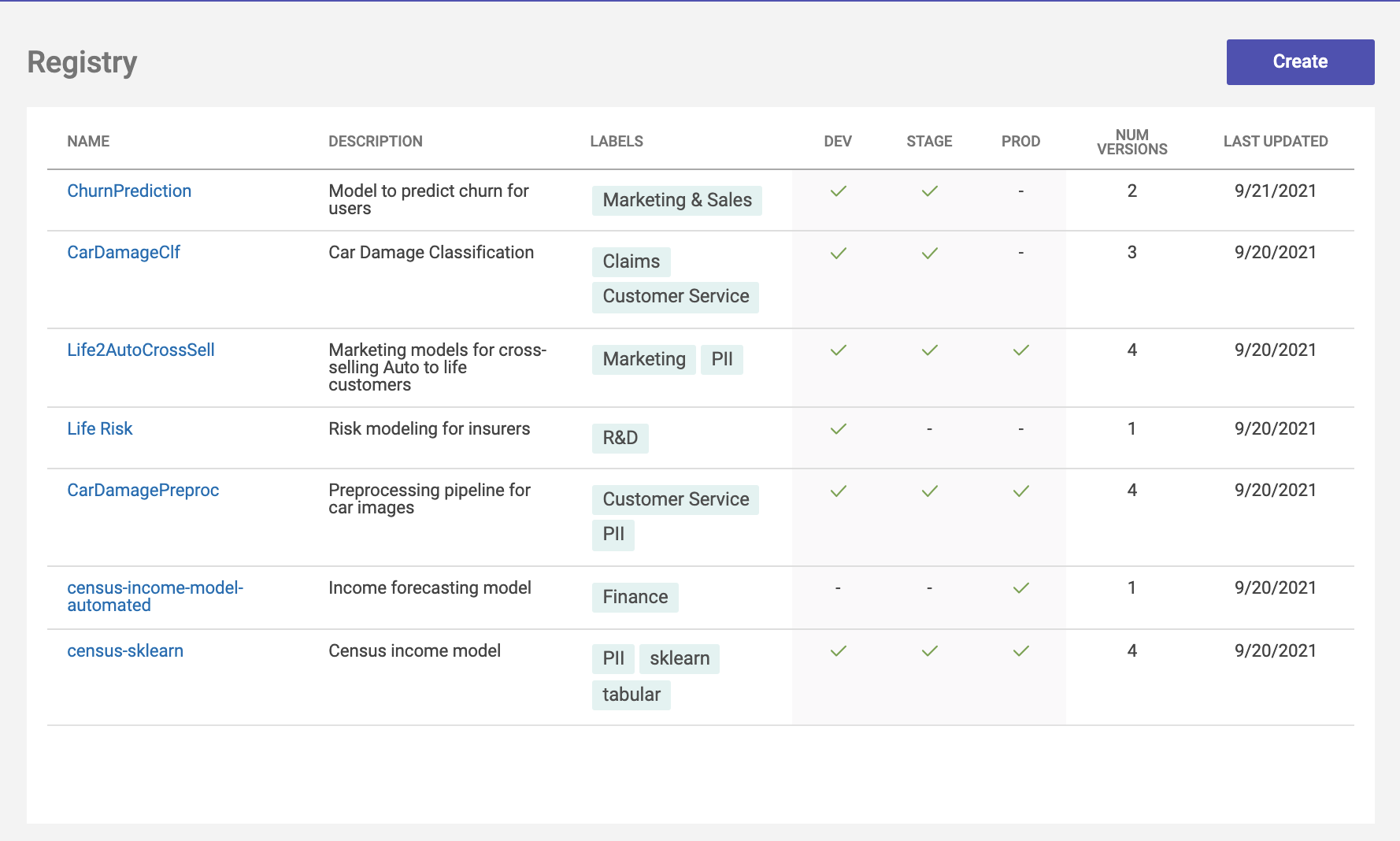
Verta's Model Registry helps ML infrastructure teams establish a repeatable model release process to ensure safe and reliable production deployment and empowers data scientists to quickly roll out new models without worrying about DevOps and release tools to achieve:
- Safe deployment - reducing production rollbacks, downtime, production incidents, and erroneous releases
- Faster model delivery - accelerate deployments and time to market
- Single pane of glass - to minimize risks and increase collaboration and visibility
To learn more, click here or schedule a demo today!
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


