
Model Versioning, Tracking, and Spreadsheets.
AI & ML is everywhere but the tools to support ML models haven’t caught up.
Artificial Intelligence and Machine Learning are getting embedded in the fabric of every product, be it our Daily News, AI-assisted therapy, or Automated investments. As we directly or indirectly delegate more decision-making to AI & ML models, the question arises:
Are the software systems supporting AI & ML models as robust and reliable as they need to be?
In this post, we talk about an often-overlooked but critical issue in AI & ML, one without which we cannot begin to trust models to run our products and businesses. We talk about model versioning.
Building an ML model
Building an ML model seems pretty straightforward from the outside: you get some data, you write code, and then you debug until it works, right? Not quite.
Whereas in traditional software development, the goal is to correctly and efficiently implement a known function, in AI & ML, the goal is to learn a function. As a result, ML model development is all about experimentation. A data scientist will process data, create features, train and test the model, and depending on the results, go back and update the data or model. Rinse-and-repeat.
So how many models do data scientists build on average?
To quantify the number of models built during a typical modeling project, during my Ph.D., we analyzed data from Kaggle competitions. The table below shows the number of submissions made by winning teams across ten different Kaggle competitions.

We found that winning teams routinely build multiple hundreds of models before arriving at the winning model. Moreover, since teams only submit their `best` models, we estimate that the total number of models built by a team is an order of magnitude larger.
What is surprising is that in spite of the iterative nature of modeling, we find that Kaggle teams don’t always think ahead to versioning. They reactively and selectively track their models, often losing the ability to examine how their past experiments performed and inform future experiments.
So why version models?
- Never Lose Knowledge: In an AI & ML team, if all knowledge about a model resides with one person or on their laptop, all that knowledge is instantly gone when this person leaves the company or project. Someone else on the team has to spend hours re-doing all of his or her hard work. In contrast, having a central model versioning system allows work to be centrally tracked and knowledge to be transferred easily.
- Model reproducibility: Given the empirical nature of ML development, it is near-impossible to remember “What dataset version did I use for this result?”, “What initialization did I use for the weights of this neural network?”, or “What feature engineering did I apply to this data?” This information becomes crucial when re-creating a model, e.g., when a production model needs to be rolled back to a previous version or the results in a research paper have to be extended to a new dataset. Without robust versioning, reproducibility is a pipe-dream.
- Meta-analyses: As a project stretches over multiple months, an AI & ML team will build hundreds of models. A central versioning system enables the team to get visibility into the experiments performed so far, spot trends and outliers, and strategies that remain unexplored.
- Debugging: Like code, models need debugging. Except now, the debugging involves not only code but also features, parameters, and domain knowledge. A versioning system gives you the tools to compute diffs between models, examine similar models from the past, and formulate hypotheses as to why a model doesn’t behave as expected.
- Auditing: Lots can be said about this! How did this model come to be? What iterations did it go through? And if you are in a regulated industry, a paper trail describing why you picked this model and feature-set over so many others is essential to answer an audit inquiry. A versioning system that tracks all modeling experiments can significantly reduce or, if done right, eliminate the overhead of preparing documents for an audit.
What are the common hacks to versioning today?
Without robust tools to version models, data scientists and ML engineers have resorted to many creative, but inadequate, workarounds. Here are a few that might seem familiar.
1. Folder structure as a versioning system
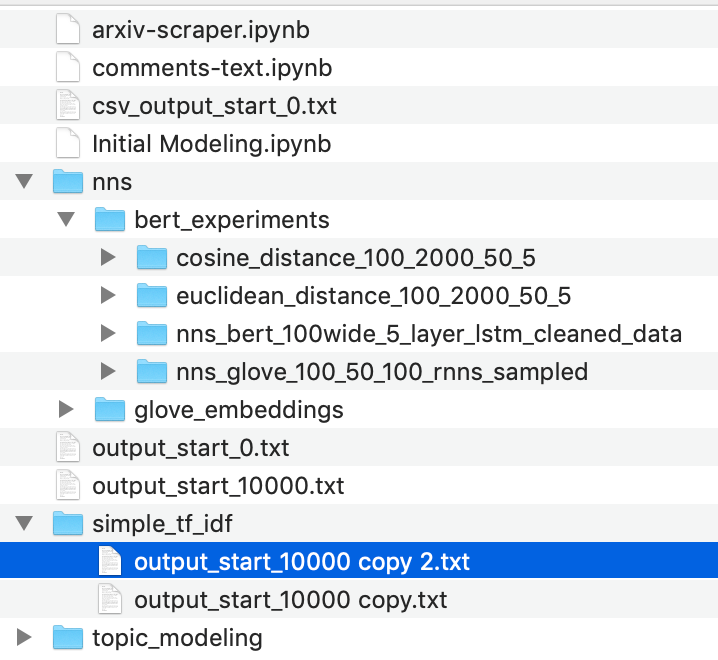
Many data scientists (myself included) have at some point used folders to track different versions of our models. Multiple blogs (e.g., here, here) build on this method and recommend fixed folder structures for tracking datasets, models, outputs, etc. While this solution might work for individual researchers, it breaks down when data is stored only on a local machine, or when different teams prefer different organizational methods, or when programmatic access to this data is necessary (e.g., find me the model with the highest accuracy for this project)
2. The trusty spreadsheet
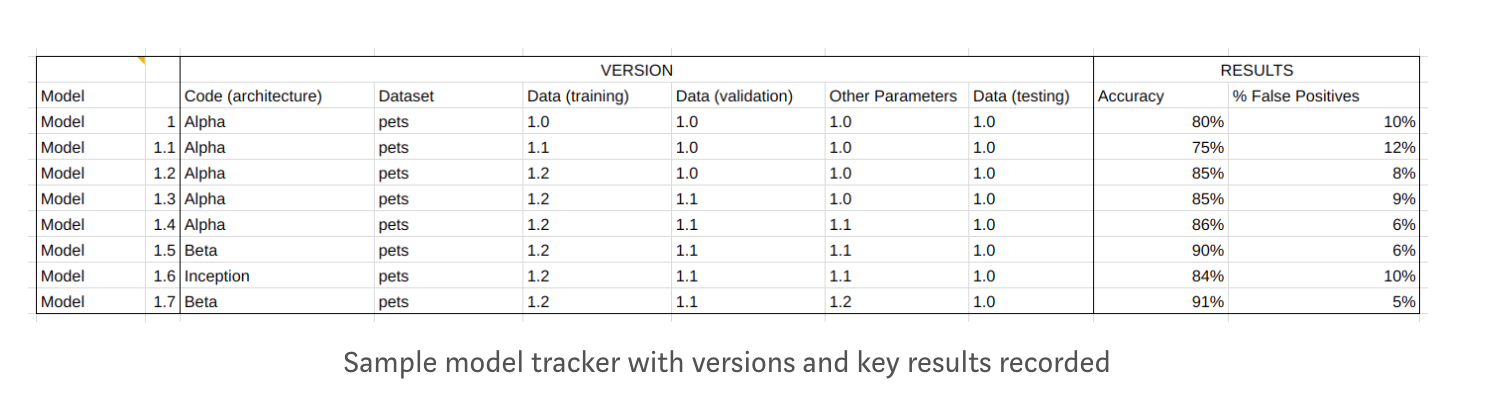
It’s true that spreadsheets are very powerful and being able to do a quick pivot table is magical. But the heterogeneity of ML experiments cannot be captured in a spreadsheet — the code changes dozens of times, the number of hyperparameters varies almost with every execution, uniquely naming architectures is near-impossible, and, most importantly, each data scientist needs to remember to update the spreadsheet after every experiment. That never happens, just look at team wikis.
3. Comments. Pure and simple.

The screenshot above is from an actual Kaggle kernel and left me speechless. Data scientists deserve better than having to track versions as comments. A software engineer having to do this would likely quit.
But doesn’t Git solve model versioning?
I get this question a lot! I ❤ git and I can’t imagine writing code without it. But code versioning, fundamentally, would solve only part of the model versioning problem. This is because:
Model = Code + Dataset + Config + Environment
Git is fantastic for the first piece, not the rest. You must version code, but you can’t only version code. Figure out a way to version your data. Figure out a way to version your hyperparameters and other config parameters. Figure out environment versioning. Now, you’re getting somewhere.
The Future: Purpose-built model versioning systems
As models become the new code and run large parts of our products and businesses, we require much more rigorous and robust tooling for models. And the first order of business is to get a model versioning system in place. Not just a patched-up system, but one that is purpose-built for models — one that is designed with the empirical nature of model development in mind and is equipped to handle the interplay between models, data, config, and environment.
At MIT, we built ModelDB, one of the first purpose-built, open-source model management systems. ModelDB takes a model-centric view of the world and provides the ability to track models, hyperparameters, metrics, tags, and pipelines — any metadata you might need about a model. In addition, it provides GUI and API-based access to all model information. Since its release, ModelDB has been used by research groups, AI-first companies, and financial institutions.
At Verta, we have extended ModelDB to provide full model reproducibility, including data, code, config, and environment versioning. Similar to ModelDB, models are first-class citizens in the Verta platform and the system is built expressly to support the full model lifecycle.
Between ModelDB and Verta, we have logged hundreds of thousands of models and counting! Data scientists using model versioning are seeing tangible improvements in productivity due to better visibility, never having to lose work again, and ease of collaboration.
Just like Git and GitHub/GitLab/BitBucket fundamentally changed the way software is developed, so will model versioning systems change the way models are developed.
TL;DR: So what can you do?
- Educate your team on model versioning: this blog, papers here and here.
- Check out open-source ModelDB here or sign up for a Verta trial here.
- Already have a home-grown system? Drop us a line and we’d be happy to help optimize. If your system already rocks, we’d be glad to profile you on our blog!
- If you live in the SF Bay Area, join us at the new Agile AI & ML meetup and help drive community standards in this space.
About Manasi:
Manasi Vartak is the founder and CEO of Verta.ai, an MIT-spinoff building software to enable production machine learning. Verta grew out of Manasi’s Ph.D. work at MIT CSAIL on ModelDB. Manasi previously worked on deep learning as part of the feed-ranking team at Twitter and dynamic ad-targeting at Google. Manasi is passionate about building intuitive data tools like ModelDB and SeeDB, helping companies become AI-first, and figuring out how data scientists and the organizations they support can be more effective. She got her undergraduate degrees in computer science and mathematics from WPI.
About Verta:
Verta builds software for the full ML model lifecycle starting with model versioning, to model deployment and monitoring, all tied together with collaboration capabilities so your AI & ML teams can move fast without breaking things. We are a spin-out of MIT CSAIL where we built ModelDB, one of the first open-source model management systems.
![]()
Thanks to Natalie Bartlett, Ravi Shetye, and Shantanu Joshi.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


