Machine learning (ML) is becoming an increasingly standard part of application development. A recent index from Deloitte shows how companies in virtually all industries are operationalizing ML to augment processes, launch AI-enabled products for customers, and (ultimately) drive greater business value. Once an ML model has been trained to recognize patterns in datasets, companies can make (and fine-tune) predictions based on new data. It doesn’t take a data scientist to understand how these insights can help drive business.
Since you’re reading this, you probably already understand that ML is a rapidly evolving discipline. The ecosystem (tools and processes) for moving machine learning models into production simply is not mature yet. Operationalizing ML (especially at scale) isn’t easy.
At Verta, we’ve noticed a fundamental misunderstanding that plagues many companies on their ML journey. Oftentimes, businesses try to adapt tried and true DevOps processes used to write traditional software to execute the unfamiliar task of Machine Learning Operationalization (MLOps). But a copy/paste approach between DevOps and MLOps rarely works. There are three main reasons why:
-
Creating a model is not writing an application
-
Consuming models is not importing software
-
Debugging models is not debugging software
Throughout this article, we’ll draw a parallel between developing a library and developing a model — and show why MLOps requires a new kind of approach.
1. Creating a model is not writing an application
Model development is sometimes described as “creating an application” or “a library.” While that comparison might seem helpful in one sense, it actually falls woefully short and demonstrates a fundamental misunderstanding of the nature and complexity of ML models. Because with ML, you’re not actually writing the software; the computer is.
Imagine if a software engineer’s routine of writing code involved:
- Creating a teaching framework to tell someone else how to get better at solving for a specific task
- Using a very large number of tests to evaluate them
But you couldn’t actually communicate with them. They’re not able to understand what you’re trying to achieve and have no concept about the world besides what you add to your teaching framework. At the end of the process, you have a binary to use that should solve the problem.
This change of mentality from “you write the functionality” to “you instruct something to write the functionality” requires a fundamental change of processes and practices.
With ML, data scientists need to manage a potentially multiple-step process to generate test scenarios, which are based on data given to the model. These steps occur across teams and with extended time frames, driven by automated processes like daily ETL jobs. You cannot be confident that the tests are correct anymore as you don’t have the time to go through each individual test yourself. If one test starts to fail but on average we pass more tests, does that mean that the functionality is better? Being able to instruct the machine what “better” means and being able to evaluate it become problems that need to be encoded.
In the end, ML models result in a black box library that you are not able to understand. This library should have all the usual things we come to expect from libraries, such as documentation and APIs. But (for example) APIs in ML models are fundamentally different, and much more complex. The traditional constraints and functionality of an API in executable software quickly go out the window when outputs no longer fit into clear buckets and they are constantly learning and adapting.
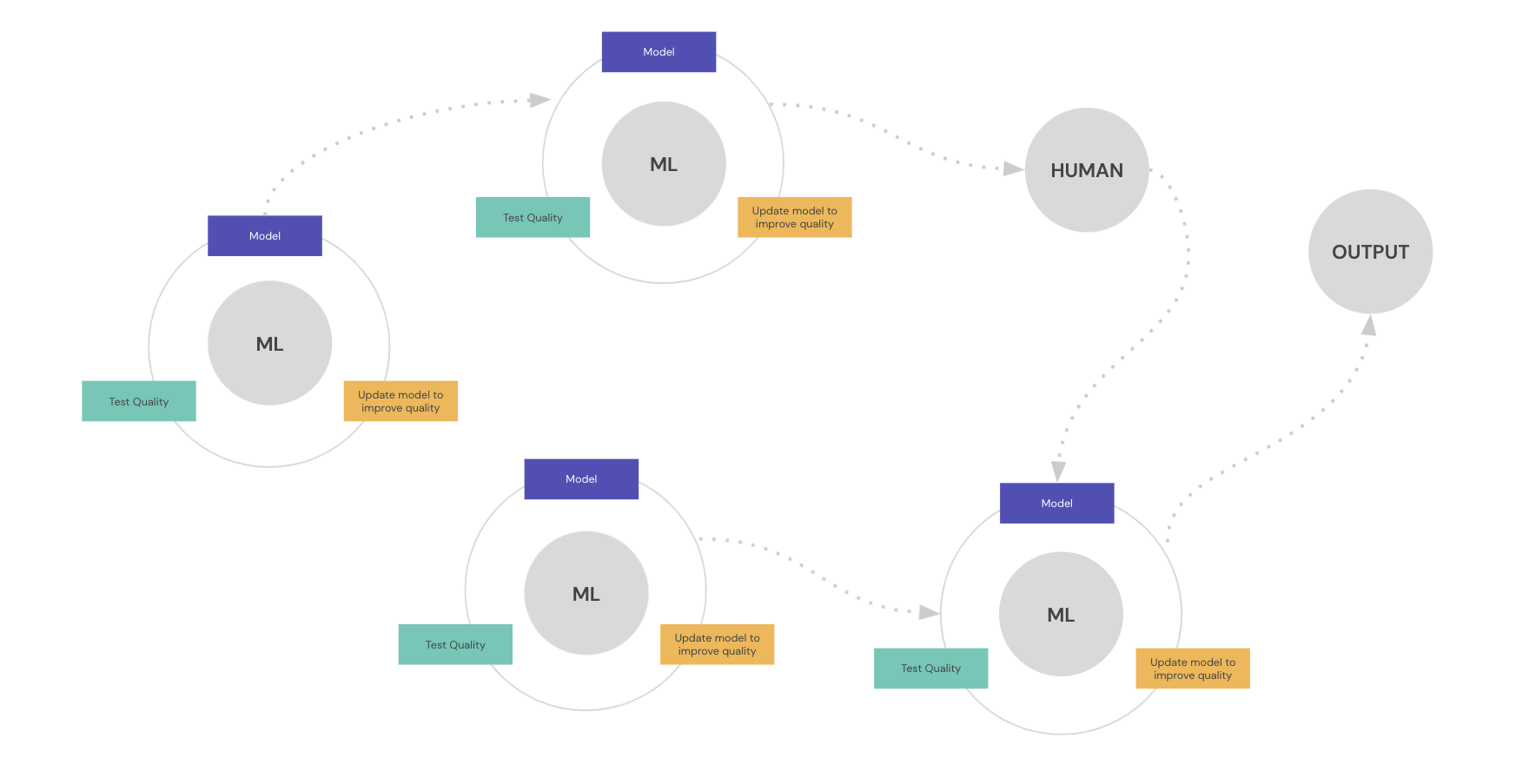
2. Consuming models is not importing libraries
APIs and operational needs break down due to the ML ecosystem. Although models provide binary interfaces for you to compute against them, two models with the same interface might not perform the same computation. Two models solving the same task on the same dataset might provide very different results for each particular sample. Since our evaluation of model quality is usually done in aggregation (e.g. accuracy), the effect of the model on individual cases might be wildly different.
This goes against the intuition of APIs in software. As an industry, we have reached semantic versioning as the way to communicate the compatibility of software. But due to the nature of the way ML works, any update to a model can change the results of the library considerably. For example, an insurance company might need to file with their governing body that outputs above 0.7 for the model are deemed unsafe and cause the premium cost to go higher. But from model to model, they now need to ensure their updates satisfy more constraints than just improving quality.
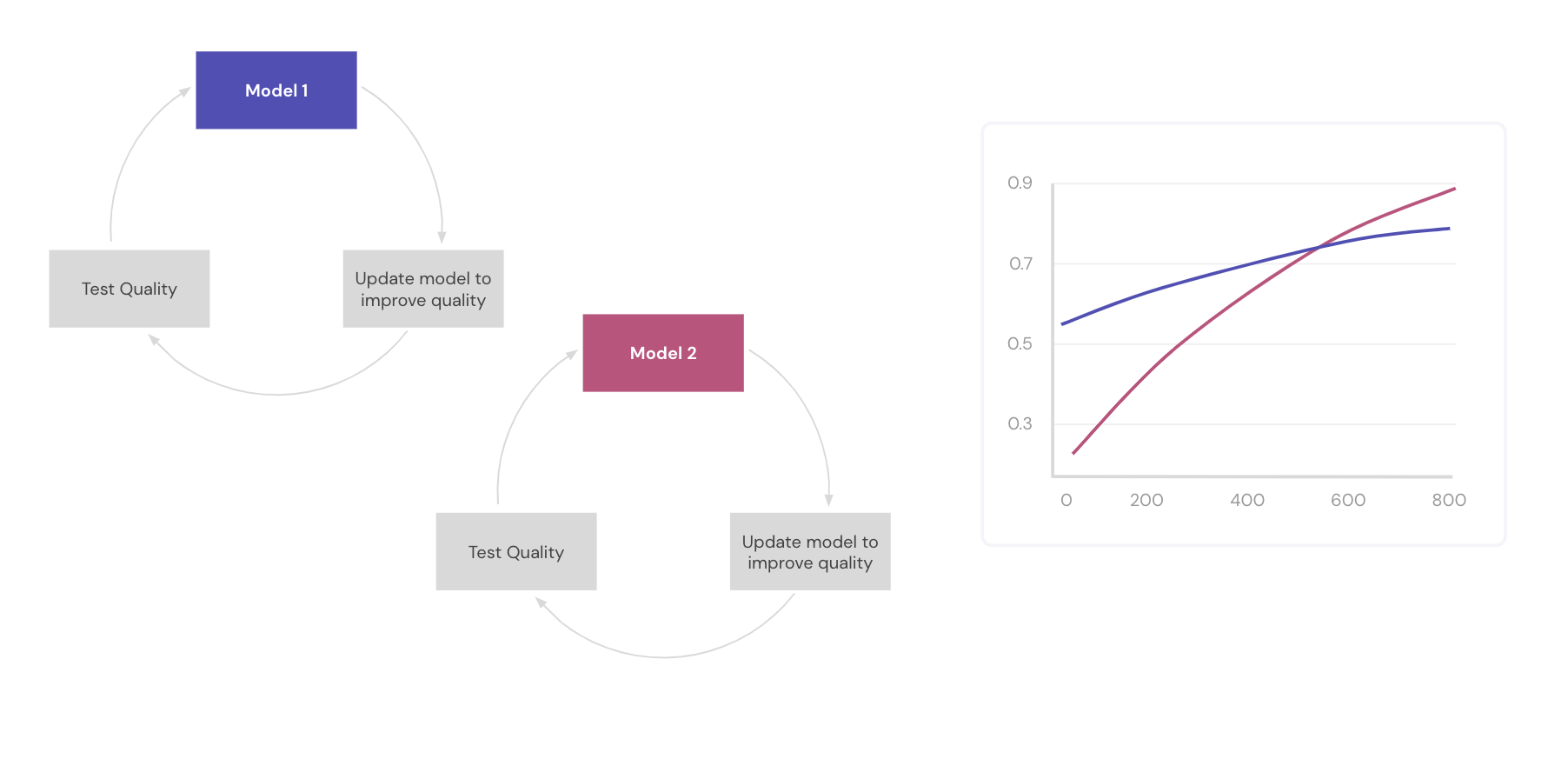
Besides correctness, the trade-off between performance and flexibility becomes painfully obvious in ML applications. From simple things like out-of memory errors, low CPU use, or high latency to more complex elements like dynamic batching, quantization, and libraries specialization, the ML ecosystem is full of challenges. The usual challenges of operationalizing software are still present, but ML models add another layer of complexity.
3. Debugging models is not debugging software
One of the most useful tools a developer has in their arsenal is a debugger. The ability to go into code, step through it line by line, make modifications and see how the machine behaves is fantastic. Using a debugger, software teams quickly find and understand root issues and bugs, so that we can fix our code. However, developers often can’t use debuggers in production, so we resort to things like logs and traces to understand (and hopefully reproduce) performed computations.
When it comes to ML, debugging tools simply don’t apply. Oftentimes, a data scientist or ML engineer can’t look at a model’s variables and visually check if they make sense. There might be some internal representation of data, like a word vector, but you won’t be able to step through this internal logic the way you’d be able to go through executable software code. Not only is this information not comprehensible by humans, it also doesn't make a lot of sense in isolation. To understand what is going wrong, you have to compare the aggregated behavior of multiple points. (For example, are many of my predictions going to a class I did not expect?) So the idea of stepping through the code and making sure it makes sense does not always work.
In a DevOps production environment, logging and tracing track what calls have been made and record the flow of execution. But in the case of ML, the system might be misbehaving due to incorrect computations — even if the flow looks right. So we have to actually inspect the data going through, which is a totally different challenge of building data collection and analysis pipelines.
Debugging models is still an active area of research, so being able to diagnose the model to then diagnose the code beneath the model is not a feasible solution for many cases today.
(Image Credit: Lightstep)
Conclusion
Companies looking to introduce or scale ML across their business should consider options for integrating ML into your product, what kind of guarantees you need to make, and what you’re willing to sacrifice. Expectations need to be communicated across your model development organization. Product requirements must be supported by tooling and internal processes.
A company’s ecosystem for creating software (DevOps) is one part of the foundation of MLOps — since operationalizing ML always requires code. But DevOps as a discipline is only one part of the picture. The whole process of creating, using, and understanding ML applications requires a completely different skill and toolset than software alone.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


